美团技术团队精选论文解读
美团技术团队有多篇论文被ACM SIGIR 2022收录,这些论文涵盖了观点标签生成、跨域情感分类、对话摘要领域迁移、跨域检索、点击率预估、对话主题分割等多个技术领域。本文精选了10篇论文做简要介绍(附下载链接),希望能对从事相关研究的同学有所帮助或启发。
SIGIR是信息检索方向的国际顶级会议(CCF-A类)。第 45 届国际信息检索大会(The 45th International ACM SIGIR Conference on Research and Development in Information Retrieval,SIGIR 2022)已于上周(2022年7月11日-15日)在西班牙马德里举行,同时也支持线上参会。本次会议共收到 794 篇长文投稿,其中 161 篇长文被录用,录用率约 20%;共收到 667 篇短文投稿,其中 165 篇短文被录用,录用率约 24.7%。

论文01:Personalized Abstractive Opinion Tagging
|下载地址:https://dl.acm.org/doi/pdf (Full Paper)
| 论文作者:赵梦雪(美团),杨扬(美团),李淼(美团),王金刚(美团),武威(美团),任鹏杰(山东大学),Maarten de Rijke(阿姆斯特丹大学),任昭春(山东大学)
| 论文简介:观点标签是一组总结用户对产品或服务感受的短文本序列,通常由针对产品特定方面的一组短句组成。相较于推荐理由、方面标签、产品关键词等自然语言文本,观点标签能兼顾信息的完整性和关键信息的顺序性问题。关键词描述了该商户的基本信息,推荐理由可看作该商户下真实用户评论的高度浓缩,而观点标签“肉质很新鲜”则更完整地表达了当前用户对于该商户的“食材新鲜”方面的关键信息。
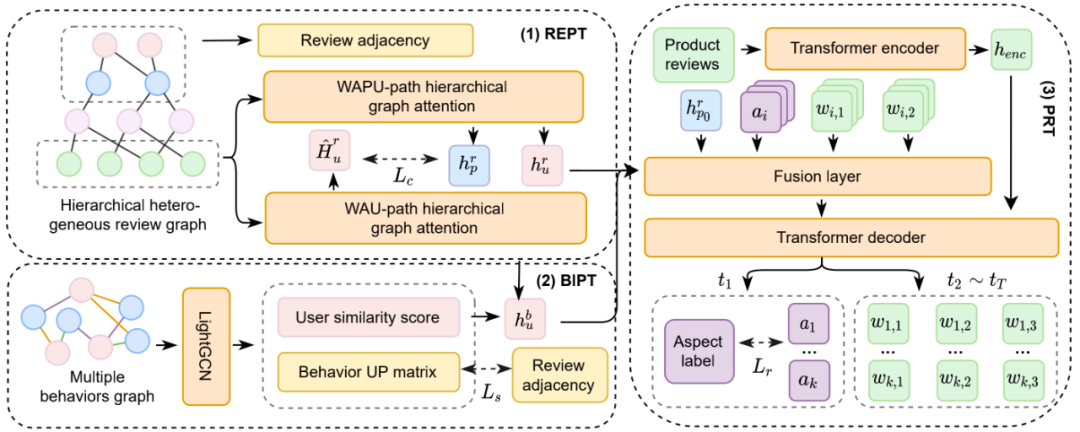
现有观点标签的标签顺序,只反映了基于统计信息的大众偏好,忽略了不同用户的个性化偏好。本文提出一种个性化的观点标签生成框架POT。基于产品评论提取产品关键信息,并通过用户评论和用户行为追踪用户的显式和隐式偏好,以确定关键信息的顺序,从而保证产品信息依据用户的感兴趣程度排列。我们设计了一个基于评论的层次异构图联合建模了用户、产品、方面标签和评论中的词,通过节点间深层次的信息交互,挖掘用户和产品之间的潜在关系,缓解了评论的稀疏性问题。同时,我们基于用户对产品的点击、收藏和购买行为构建了多类行为图,通过探索用户之间的相似关系进一步增强用户偏好表示。我们针对评论数据和行为数据的不同特点设计了不同的去噪模块以保证用户偏好表示的准确性。我们构建了基于大众点评真实数据的个性化观点标签数据集PATag,并在生成指标和排序指标中取得了良好的效果。此论文为NLP CIKM 2020论文《Query-aware Tip Generation for Vertical Search》的后续工作。
论文02:Graph Adaptive Semantic Transfer for Cross-domain Sentiment Classification
| 下载地址:https://arxiv.org/pdf (Full Paper)
| 论文作者:张凯(美团),刘淇(中国科学技术大学),黄振亚(中国科学技术大学),张梦迪(美团),张琨(合肥工业大学),程明月(中国科学技术大学大学),武威(美团),陈恩红(中国科学技术大学)
| 论文简介:跨域情感分类(CDSC)旨在使用从源域中学习到的可迁移语义信息来预测未标记目标域中评论的情感极性。目前针对该任务的研究更多地关注句子层面的序列建模,很大程度上忽略了嵌入在图结构中的丰富的域不变语义信息(即词性标签和依赖关系)。作为探索与理解语言理解特征的一个重要方面,自适应图表示学习近年来发挥了至关重要的作用,尤其是在许多基于图表征模型的传统NLP任务中。例如在细粒度的情感分析(ABSA)任务中,利用图结构中的句法信息来增强Aspect的语义表示已经成为SOTA模型的基本配置。
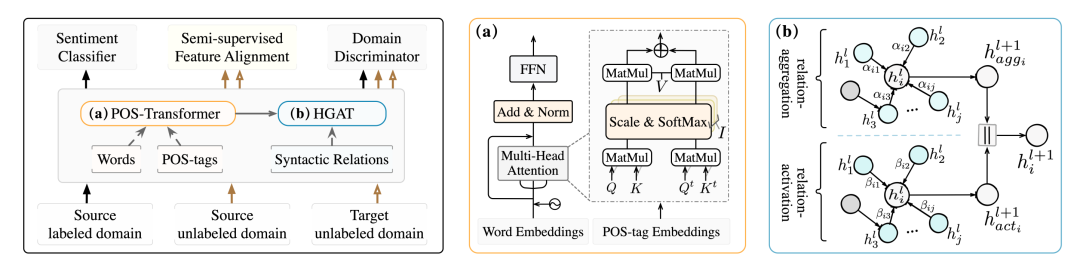
在本论文中,我们旨在探索从CDSC中的类图结构中学习不变语义特征的可能性。我们提出了图自适应语义迁移(Graph Adaptive Semantic Transfer, GAST)模型,这是一种自适应句法图嵌入表征方法,能够从单词序列和句法图中学习域不变语义。具体地说,我们首先设计了一个POS-Transformer模块来从单词序列以及词性标签中提取序列化的语义特征;然后,我们设计了一个混合图注意(Hybrid-GAT)模块,通过考虑可迁移、域共享的图依赖关系来生成基于句法的通用语义特征;最后,我们设计了一个集成的自适应优化策略(Integrated aDaptive Strategy, IDS)来指导两个模块的联合学习过程。在四个公共数据集上进行的广泛实验证明,GAST的有效性优于一系列最先进的模型。
论文03:ADPL: Adversarial Prompt-based Domain Adaptation for Dialogue Summarization with Knowledge Disentanglement
| 下载地址:https://dl.acm.org/doi/pdf (Full Paper)
| 论文作者:赵璐璐(北京邮电大学),郑馥嘉(北京邮电大学),曾伟豪(北京邮电大学),何可清(美团),耿若彤(北京邮电大学),江会星(美团),武威(美团),徐蔚然(北京邮电大学)
| 论文简介:领域自适应是机器学习中的一个基本任务。在本文中,我们研究对话摘要任务中的领域迁移问题,试图借助源域的有标注数据迁移到无标注或少标注的目标域,进而提升低资源目标域下对话摘要的生成效果,可用于解决实际场景中小业务数据匮乏的挑战。传统的对话摘要领域迁移方法往往依赖于大规模领域语料,借助于预训练来学习领域间知识。该方法的缺点是实际语料收集难,对算力要求高,针对每一个目标域都需要进行耗时的预训练过程,效率低。
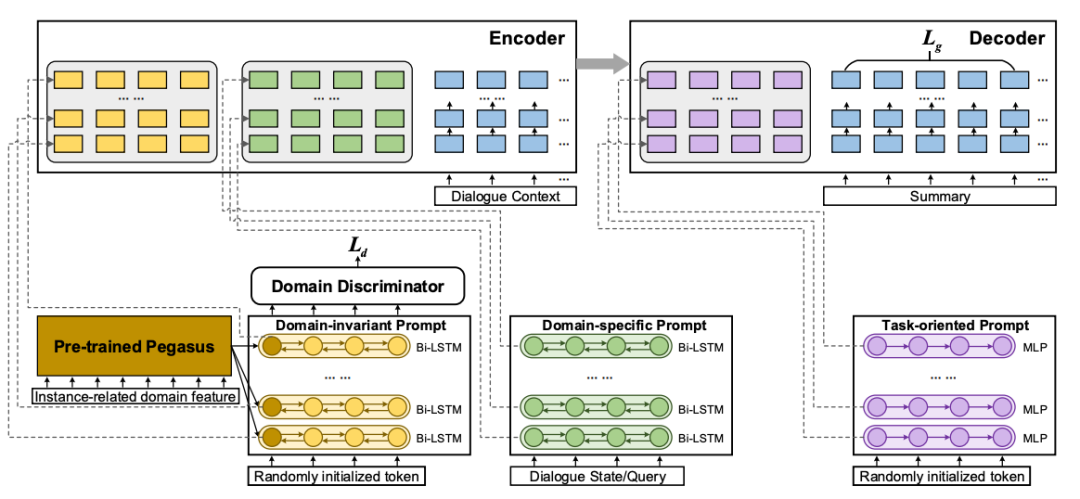
本文从微调的角度出发,提出了一种轻量级的解耦知识迁移方法ADPL,无需大规模的预训练过程,仅仅利用源域数据和少量的无标注目标域数据,即可实现高质量的对话摘要生成。具体来说,我们基于Prompt Learning的思想,针对对话摘要任务中的领域迁移问题,提出了三种特定的prompt结构:Domain-Invariant Prompt (DIP)、Domain-Specific Prompt (DSP)和Task-Oriented Prompt (TOP),其中DIP用来捕获领域间的共享特征,DSP用来建模领域特有知识,TOP用来促进生成流畅的摘要。在训练中,我们仅仅更新这些Prompt相关的参数就可以实现领域间知识的解耦和迁移,相比较之前的预训练方法,训练高效环保,对机器的显存要求显著降低。同时,我们基于两个大规模的对话摘要数据集QMSum和TODSum构建了对话摘要领域迁移评测集,在两个评测集上取得了一致的最优效果,实验结果和消融分析都证明了本文提出方法的有效性。
论文04:Structure-Aware Semantic-Aligned Network for Universal Cross-Domain Retrieval
| 下载地址:https://dl.acm.org/doi/pdf (Full Paper)
| 论文作者:田加林(美团), 徐行(电子科技大学),王凯(电子科技大学),曹佐(美团),蔡勋梁(美团),申恒涛(电子科技大学)
| 论文简介:跨域检索(Cross-Domain Retrieval,CDR)旨在实现基于内容的多域图像表征对齐和检索;当域间差异过大时,也称之为跨模态检索。传统的CDR方法只考虑训练和测试数据来源于相同的域和相同类。然而,实际应用场景中测试样本常来自于未见类,或者未见域,又或者两者皆是。卷积神经网络已经成为CDR任务主流,然而,由于卷积操作的内在局部性,CNN在对物体的全局结构信息进行建模时受到明显的制约。
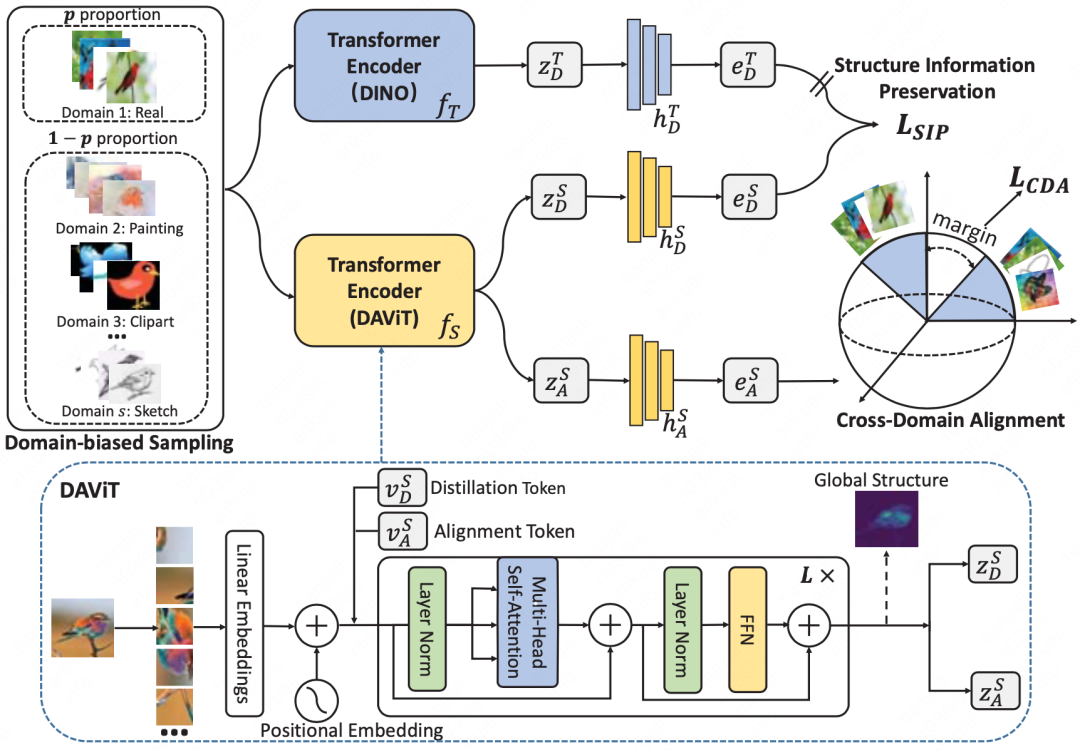
基于上述问题,我们提出通用跨域检索(Universal Cross-Domain Retrieval, UCDR),其测试数据可以来源于未见类、未见域或者两者结合,方法中我们使用基于Vision Transformer(ViT)的结构感知语义对齐网络,利用ViT的能力来建模物体的全局结构信息。具体而言,我们将自监督预训练的ViT模型和微调模型整合到一个框架下,通过对齐软标签防止微调模型遗忘全局结构信息,提升微调模型泛化性;通过可学习的类原型在超球空间对齐多域表征,提升微调模型的判别性。实验结果表明,我们的方法在跨域检索任务上远超现有算法,成功实现跨域表征对齐和模型泛化性。
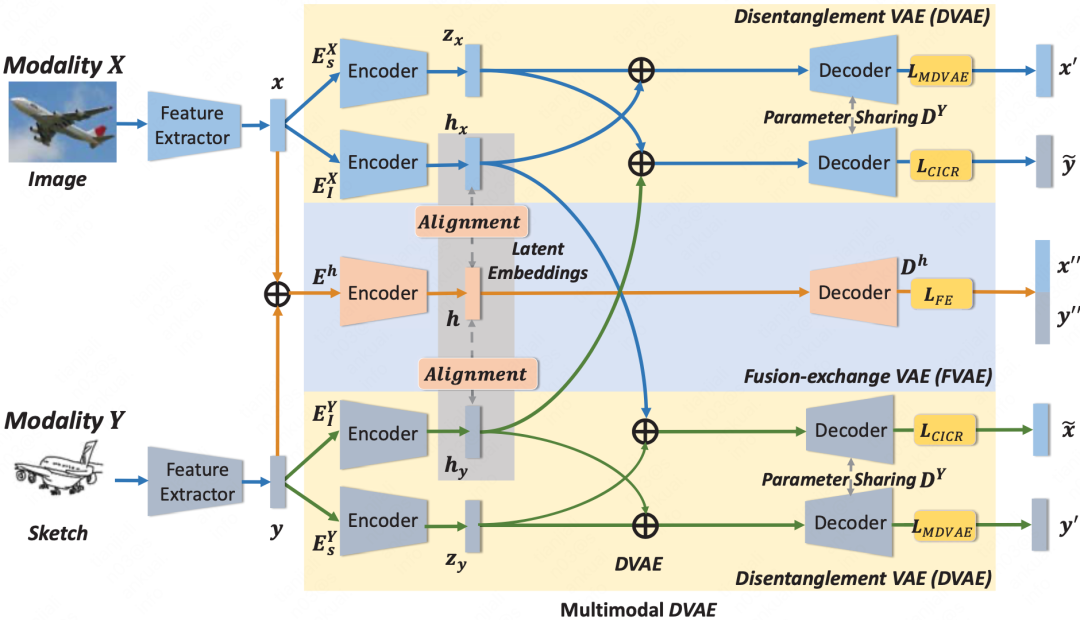
论文05:Multimodal Disentanglement Variational Autoencoders for Zero-Shot Cross-Modal Retrieval
| 下载地址:https://dl.acm.org/doi/pdf (Full Paper)
| 论文作者:田加林(美团),王凯(电子科技大学),徐行(电子科技大学),曹佐(美团),沈复民(电子科技大学),申恒涛(电子科技大学)
| 论文简介:测试集由未见类组成是零样本跨模态检索(Zero-Shot Cross-Modal Retrieval,ZS-CMR)关注的一个实际的检索场景。现有方法通常采用生成模型作为主要框架,学习联合潜在嵌入空间表征以缓解模态差异。一般来说,这些方法主要依靠额外的语义嵌入实现跨类的知识迁移,并且不自觉地忽略了生成模型中数据重建方式的影响。
基于上述问题,我们提出一个称为多模态解耦变分自编码器(MDVAE)的ZS-CMR模型,它由两个特定于模态的解耦变分自编码器(DVAE)和一个融合交换自动编码器(FVAE)组成。具体来说,DVAE把每种模态的原始表征分解为模态不变特征和特定于模态的特征。FVAE通过重构和对齐过程来融合和交换多模态数据的信息,而无需额外的语义嵌入。此外,我们还提出了一个新颖的反直觉交叉重构方案,以提高模态不变量特征的信息量和通用性,从而实现更有效的知识迁移。提出的方法在图像-文本和图像-草图检索任务中取得明显性能提升,建立了新的SOTA结果。
论文06:Co-clustering Interactions via Attentive Hypergraph Neural Network
| 下载地址:https://dl.acm.org/doi/pdf (Full Paper)
| 论文作者:杨天持(北京邮电大学),杨成(北京邮电大学),张路浩(美团),石川(北京邮电大学),胡懋地(美团),刘怀军(美团),李滔(美团),王栋(美团)
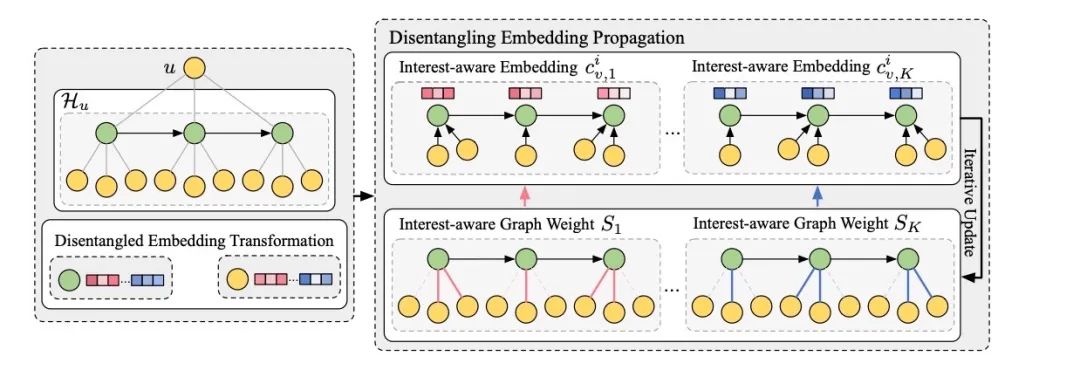
| 论文简介:随着如电商平台中的用户-商家/商品的点击或者购买等交互数据的快速增多,人们提出了许多聚类方法用于发现交互模式,例如在外卖场景中的“白领经常在下午购买咖啡以提升工作效率”,从而作为先验知识来帮助下游任务。考虑到交互可以被视为多个对象之间发生的一个动作,大多数现有方法将对象及其成对关系建模为图中的节点和边。然而,他们只对实际的完整交互中的部分信息进行了建模和利用,即要么将一个完整交互分解成若干个成对的子交互以进行简化,要么只专注于对某些特定类型的对象进行聚类,这限制了聚类的性能和解释性。
在本文中,针对这一问题,我们提出通过注意力超图神经网络对交互进行协同聚类(CIAH)。具体来说,在通过超图对交互进行更全面的建模(包括用户属性、商家属性、菜品属性、时空属性等)后,我们提出一个注意力超图神经网络来编码完整交互,其中使用注意机制来选择重要的属性以作为聚类结果的解释。然后,我们引入了一种显著性方法来指导注意力机制的学习,以使其与属性的真实重要性更加一致,称为基于显著性的一致性。此外,我们还提出了一种新颖的协同聚类方法来对交互的表示和相应的属性选择分布进行协同聚类,称为基于聚类的一致性。实验表明CIAH在公开数据集和美团数据集上均显著优于最先进的聚类方法。

论文07:DisenCTR: Dynamic Graph-based Disentangled Representation for Click-Through Rate Prediction
| 下载地址:https://dl.acm.org/doi/pdf (Short Paper)
| 论文作者:王一帆(北京大学),覃义方(美团),孙昉(美团),张博(美团),侯旭阳(美团),胡可(美团),程佳(美团),雷军(美团),张铭(北京大学)
| 论文简介:点击率(CTR)预估在推荐系统、搜索广告等下游业务中有着重要的应用。现有工作常常通过用户行为序列刻画用户兴趣,却未能捕捉用户实时兴趣的多样性(Diversity)和流动性(Fluidity)。为了更加准确地刻画用户实时兴趣,提升CTR预估质量,该论文提出了基于动态图的解耦合表示框架DisenCTR,对用户不断变化的多兴趣进行建模。DisenCTR在动态时序U-I子图上通过动态路由机制提取用户多兴趣的解耦合表示(Disentangled Representation),并使用混合霍克斯过程(Mixture of Hawkes Process)模拟用户历史行为中的自激效应。该模型在公开数据集和美团私有数据集上均取得了显著的性能提升。
论文08:Hybrid CNN Based Attention with Category Prior for User Image Behavior Modeling
| 下载地址:https://arxiv.org/pdf (Short Paper)
| 论文作者:陈鑫(美团),唐庆涛(美团),胡可(美团),徐越(美团),邱世航(香港科技大学),程佳(美团),雷军(美团)
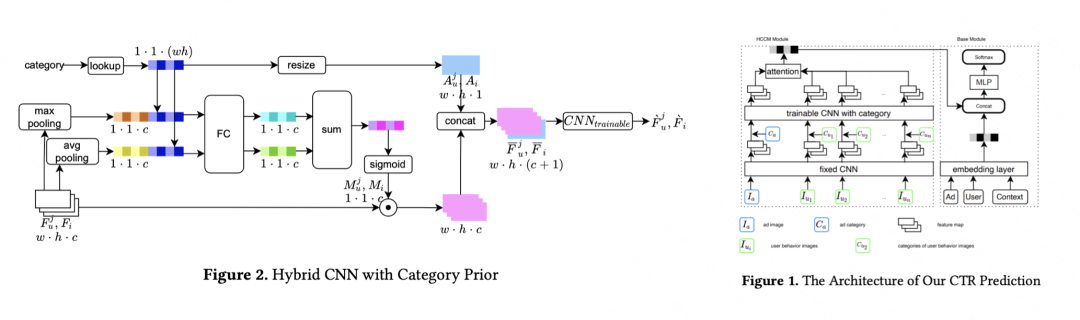
| 论文简介:在推荐广告场景中,每个POI会展示其对应的图片,展示的图片通常会影响用户是否点击这个POI,这意味着建模用户对图片的偏好有助于CTR建模。业界对图片建模大多数停留在POI侧,较少关注用户侧图片行为序列的建模。目前现有的用户创意图片行为序列模型通常使用Two-Stage的模型结构,即在第一阶段通过现成的CNN网络提取创意图片的Embedding,第二阶段使用图片Embedding和CTR模型联合训练,这种两阶段架构对于CTR建模是次优的,除此之外现有的CNN缺乏场景属性相关的类别先验,会导致CNN提取场景任务无关的特征,从而限制了CNN的表达能力。
为此,在本文中我们设计了一种Fixed-CNN和Trainable-CNN混合的Hybrid CNN结构(HCCM),来建模用户图像行为序列。文章主要贡献:1)通过ImageNet预训练的参数初始化浅层CNN,固定浅层CNN参数的同时将深层CNN与CTR模型联合训练。2)设计了将候选图片和用户对图片的偏好相结合的图片语意Attention机制,为提升CNN在推荐广告CTR任务上的特征提取能力,HCCM将图片和图片的类别先验在Feature Map维度通过Channel Attention的方式提取类目体系相关特征。相关技术方案在到店推荐广告的所有场景(包括首页信息流推荐、商户详情页推荐和团单详情页推荐等)均取得了显著效果。
论文09:Dialogue Topic Segmentation via Parallel Extraction Network with Neighbor Smoothing
| 下载地址:https://dl.acm.org/doi/pdf (Short Paper)
| 论文作者:夏今雄(美团),刘操(美团),陈见耸(美团),李宇琛(美团),杨帆(美团),蔡勋梁(美团),万广鲁(美团),王厚峰(北京大学)
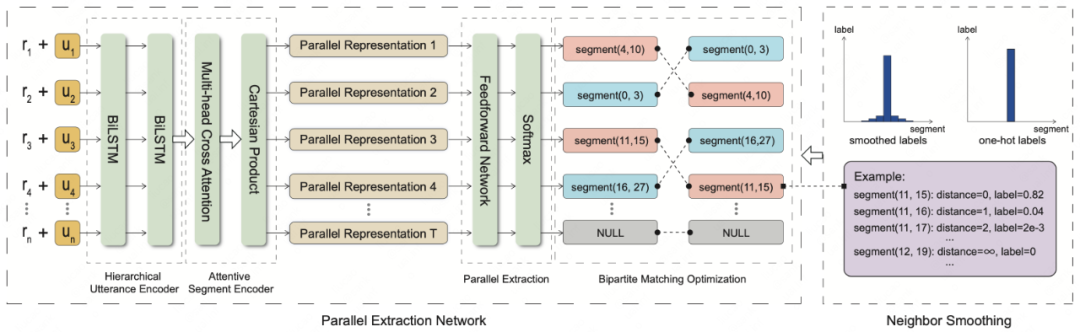
| 论文简介:对话主题分割需要将对话分割成具有预定义主题的片段。现有的主题切分研究采用两阶段范式,包括文本切分和片段标注。然而,这些方法在分割时往往侧重于局部上下文,并且没有很好地捕捉到片段间的依赖关系。此外,对话段边界的模糊性和标签噪声对现有模型提出了进一步的挑战。
为此,我们提出了基于邻域平滑的并行抽取网络 (PEN-NS) 来解决上述问题。具体来说,我们提出了并行抽取网络来执行片段提取,优化片段的二分匹配代价以捕获片段间的依赖关系。此外,我们还提出了邻域平滑来处理数据噪声和边界模糊。在基于对话和基于文档的主题分割数据集上的实验表明,PEN-NS的性能显著优于现有的模型。
论文10:Deep Page-Level Interest Network in Reinforcement Learning for Ads Allocation
| 下载地址:https://dl.acm.org/doi/pdf (Short Paper)
| 论文作者:廖国钢(美团),石晓文(美团),王泽(美团),吴晓旭(美团),张楚珩(美团实习生),王永康(美团),王兴星(美团),王栋(美团)
| 论文简介:在Feed流场景下,用户在页面的行为模式受页面展示多个物品影响,单点兴趣无法建模页面内多物品的竞争关系,难以利用更丰富的请求级用户行为信息(如下刷,流失等),无法充分提取用户复杂的页面级决策模式。因此,如何利用用户的请求级行为信息,建模列表物品的竞争关系和相互影响,在重排、混排、预估等场景均有极大业务价值,是一个非常有意义也极具挑战性的问题。业界主流用户兴趣建模框架侧重通过单物品行为序列来刻画用户的兴趣,主要有三方面局限性:一是单物品序列忽略了列表中物品竞争关系;二是点击下单等单物品行为忽略了用户的页面级行为信息,对于用户行为刻画不完整;三是忽略用户感受野差异,不同用户对页面中不同区域物品的关注度有较大差异。

针对以上挑战,本文设计了基于强化学习框架的页面级深度兴趣网络框架(DPIN),利用用户的列表粒度行为信息,刻画列表广告与广告、广告与自然结果的竞争关系和相互影响,建模用户在浏览页面时复杂的决策行为模式。具体包括四方面:
- 一是基于用户历史行为构造Page-Level序列,设计页面内自注意力层对页面内竞争关系进行建模;
- 二是在点击下单行为的基础上,增加下刷、流失屏等页面级负反馈、隐式反馈信息,并对隐式反馈信息去噪;
- 三是设计不同卷积核对页面的局部视野信息进行抽取,得到多个通道的Page-Level信息,建模考虑用户感受野差异;
- 四是设计Page-Level行为匹配层,对不同通道的用户历史行为序列和当前候选序列进行整体匹配建模,提升广告分配决策效率。
本文的技术方案在美团外卖场景取得了显著效果,并完成线上大规模落地。此论文为WWW 2022论文《Cross DQN: Cross Deep Q Network for Ads Allocation in Feed》的后续工作。
写在后面
以上这些论文是美团技术团队与各高校、科研机构通力合作的成果。本文主要介绍了我们在观点标签、跨域情感分类、领域自适应、跨域检索、点击率预估、对话主题分割等技术领域做的一些科研工作。希望能对大家有所帮助或启发,也欢迎大家跟我们进行交流。
经过近3年的建设打磨,美团流水线引擎完成了服务端的基建统一,每日支撑近十万次的流水线执行量,系统成功率保持在99.99%以上。本文主要介绍美团在自研引擎建设层面遇到的挑战以及解决方 ...