Python 人工神经网络算法
1.常见神经网络算法
| 算法名称 | 算法描述 |
|---|---|
| BP神经网络 | 是一种按误差逆传播算法训练的多层前馈网络,学习算法是 δ \deltaδ 学习规则,是目前应用最广泛的神经网络模型之一 |
| RBF径向神经网络 | RBF网络能够以任意精度逼近任意连续函数,从输入层到隐含层的变换是非线性的,而从隐含层到输出层的变换是线性的,特别适合于解决分类问题 |
| LM神经网络 | 是基于梯度下降法和牛顿法结合的多层前馈网络,特点:迭代次数少,收敛速度快,精确度高 |
| FNN模糊神经网络 | FNN模糊神经网络是具有模糊权系数或者输入信号是模糊量的神经网络,是模糊系统与神经网络想结合的产物,它汇聚了神经网络与模糊系统的优点,集联想、识别、自适应及模糊信息处理于一体 |
| GMDH神经网络 | GMDH网络也称为多项式网络,它是前馈神经网络中常用的一种用于预测的神经网络。它的特点是网络结构不固定,而且在训练过程中不断改变 |
| ANFIS自适应神经网络 | 神经网络镶嵌在一个全部模糊的结构之中,在不知不觉中向训练数据学习,自动产生、修正并高度概况出最佳的输入与输出变量的隶属函数以及模糊规则;另外,神经网络的各层结构与参数也都具有了明确的、易于理解的物理意义 |
2.反向传播算法(BP)
BP神经网络是一种按误差反向传播(简称误差反传)训练的多层前馈网络,其算法称为BP算法,它的基本思想是梯度下降法,利用梯度搜索技术,以期使网络的实际输出值和期望输出值的误差均方差为最小。基本BP算法包括信号的前向传播和误差的反向传播两个过程。即计算误差输出时按从输入到输出的方向进行,而调整权值和阈值则从输出到输入的方向进行。正向传播时,输入信号通过隐含层作用于输出节点,经过非线性变换,产生输出信号,若实际输出与期望输出不相符,则转入误差的反向传播过程。误差反传是将输出误差通过隐含层向输入层逐层反传,并将误差分摊给各层所有单元,以从各层获得的误差信号作为调整各单元权值的依据。通过调整输入节点与隐层节点的联接强度和隐层节点与输出节点的联接强度以及阈值,使误差沿梯度方向下降,经过反复学习训练,确定与最小误差相对应的网络参数(权值和阈值),训练即告停止。此时经过训练的神经网络即能对类似样本的输入信息,自行处理输出误差最小的经过非线形转换的信息。
1.BP算法特点
反向传播算法(Back Propagation, BP),BP算法是利用输出后的误差来估计输出层的直接前导层误差,再利用这个误差估计更前一层的误差,如此一层一层的反向传播下去,就获得所有其他各层的误差估计。这样就形成了将输出层表现出的误差沿着与输入传送相反的方向逐级向网络的输入层传递的过程。以典型的三层BP网络为例,描述标准的BP算法。假设有一个有3个输入节点,4个隐层节点,1个输出节点的三层BP神经网络。
特点:
1、输入输出映射问题转化为非线性优化问题
2、由前向计算与误差反向传播组成
3、权重西修正量只与连接的两个节点相关
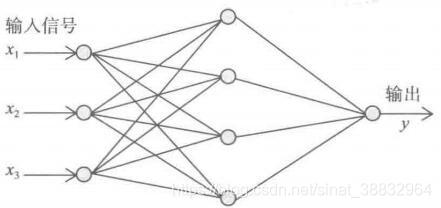
BP算法的学习过程由信号的正向传播与误差逆向传播两个过程组成。正向传播时,输入信号经过隐层的处理后传向输出层。若输出层节点未能得到期望的输出,则转入误差的逆向传播阶段,将输出误差按照某种子形式,通过隐层向输入层返回,并“分摊”给隐层 4 个节点与输入层 x 1、x 2 、x 3三个输入节点,从而获得各层单元的参考误差或误差信号,作为修改各个单元权值的依据。这种信号正向传播与误差逆向传播的各层权矩阵的修改过程,是周而复始的。权值不断修改的过程,也就是网络学习(或训练)的过程。此过程一直进行到网络输出误差逐渐减少到可接受的程度或达到设定的学习次数为止。
2.BP算法学习过程
算法开始后,给定学习次数上限,初始化学习次数为 0,对权值和阈值赋予小的随机数,一般在][−1,1] 之间。输入样本数据,网络正向传播,得到中间层与输出层的值。比较输出层的值与教师信号值的误差,用误差函数 E 来判断误差是否小于误差上线,如不小于误差上限,则对中间层和输出层权值和阈值进行更新,更新的算法为 δ 学习规则。更新权值和阈值后,再次将样本数据作为输入,得到中间层与输出层的值,计算误差 E 是否小于上限,学习次数是否达到指定值,如果达到,则学习结束。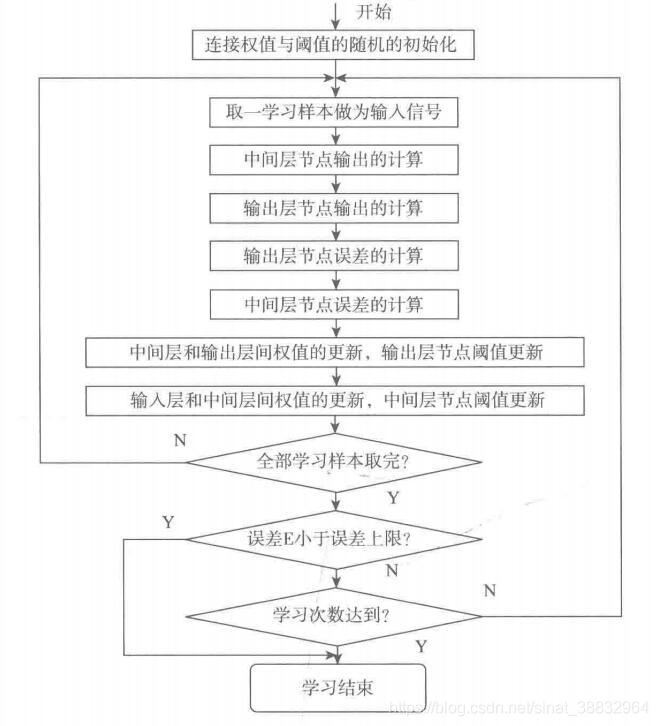
BP算法值用到均方误差函数对权值和阈值的一阶导数(梯度)信息,使得算法存在收敛速度缓慢、易陷入局部极小等缺陷。
3.BP算法实际问题
1、权重的关联性
2、对数据进行归一化和预处理。
3、样本数量的问题,网络大小的问题,越大的网络需要的样本越大,训练模式下是连接权重的5-10倍。
4、测试样本,随机划分,三分之二训练,三分之一测试。
5、训练样本必须是完备的,必须覆盖所有区域。
6、输出表示同通过编码(二进制)表示不同类别
7、适当的训练次数,防止过拟合,欠拟合。
3.径向基函数神经网络算法(RBF)
径向神经网络(RBF:Radial basis function)是一种以径向基核函数作为激活函数的前馈神经网络。RBF是20世纪80年代末提出的一种单隐层、以函数逼近为基础的前馈神经网络。随着研究日渐成熟,RBFNN以其结构简单、非线性逼近能力强以及良好的推广能力,受到各领域研究者的极大关注,被广泛应用于模式分类、函数逼近和数据挖掘等众多研究领域。
1.RBF算法特点
RBF网络一共分为三层,第一层为输入层即Input Layer,由信号源节点组成;第二层为隐藏层即图中中间的黄球,隐藏层中神经元的变换函数即径向基函数是对中心点径向对称且衰减的非负线性函数,该函数是局部响应函数。因为是局部相应函数,所以一般要根据具体问题设置相应的隐藏层神经元个数;第三层为输出层,是对输入模式做出的响应,输出层是对线性权进行调整,采用的是线性优化策略,因而学习速度较快。
2.RBF的学习方法
(1)K-均值聚类法
K-均值聚类的使用步骤:
1、得到中心和半径
2、调节权重矩阵(线性最小二乘法求权重矩阵,梯度下降法(优先使用))
(2)正交最小二乘法
3.RBF神经网络与BP神经网络进行对比
(1)RBF网络和BP网络一样可近似任何的连续非线性函数。两者的主要不同点是在非线性映射上采用了不同的作用函数。
(2) RBF网络具有惟一最佳逼近的特性,且无局部极小。
(3)求RBF网络隐节点的中心向量和标化常数是一个困难的问题。
(4)径向基函数有多种。最常用的有,高斯核函数。
(5)RBF网络用于非线性系统辨识与控制时,隐节点的中心难求。
(6) RBF网络学习速度很快。
(7)RBF网络是一种典型二层网络,BP是一种典型的三层网络。
4、RBF的MATLAB实现
演示RBF算法在计算机视觉中的应用:
SamNum = 100; % 总样本数
TestSamNum = 101; % 测试样本数
InDim = 1; % 样本输入维数
ClusterNum = 10; % 隐节点数,即聚类样本数
Overlap = 1.0; % 隐节点重叠系数
% 根据目标函数获得样本输入输出
NoiseVar = 0.1;
Noise = NoiseVar*randn(1,SamNum);
SamIn = 8*rand(1,SamNum)-4;
SamOutNoNoise = 1.1*(1-SamIn+2*SamIn.^2).*exp(-SamIn.^2/2);
SamOut = SamOutNoNoise + Noise;
TestSamIn = -4:0.08:4;
TestSamOut = 1.1*(1-TestSamIn+2*TestSamIn.^2).*exp(-TestSamIn.^2/2);
figure
hold on
grid
plot(SamIn,SamOut,'k+')
plot(TestSamIn,TestSamOut,'k--')
xlabel('Input x');
ylabel('Output y');
Centers = SamIn(:,1:ClusterNum);
NumberInClusters = zeros(ClusterNum,1); % 各类中的样本数,初始化为零
IndexInClusters = zeros(ClusterNum,SamNum); % 各类所含样本的索引号
while 1,
NumberInClusters = zeros(ClusterNum,1); % 各类中的样本数,初始化为零
IndexInClusters = zeros(ClusterNum,SamNum); % 各类所含样本的索引号
% 按最小距离原则对所有样本进行分类
for i = 1:SamNum
AllDistance = dist(Centers',SamIn(:,i));
[MinDist,Pos] = min(AllDistance);
NumberInClusters(Pos) = NumberInClusters(Pos) + 1;
IndexInClusters(Pos,NumberInClusters(Pos)) = i;
end
% 保存旧的聚类中心
OldCenters = Centers;
for i = 1:ClusterNum
Index = IndexInClusters(i,1:NumberInClusters(i));
Centers(:,i) = mean(SamIn(:,Index)')';
end
% 判断新旧聚类中心是否一致,是则结束聚类
EqualNum = sum(sum(Centers==OldCenters));
if EqualNum == InDim*ClusterNum,
break,
end
end
% 计算各隐节点的扩展常数(宽度)
AllDistances = dist(Centers',Centers); % 计算隐节点数据中心间的距离(矩阵)
Maximum = max(max(AllDistances)); % 找出其中最大的一个距离
for i = 1:ClusterNum % 将对角线上的0 替换为较大的值
AllDistances(i,i) = Maximum+1;
end
Spreads = Overlap*min(AllDistances)'; % 以隐节点间的最小距离作为扩展常数
% 计算各隐节点的输出权值
Distance = dist(Centers',SamIn); % 计算各样本输入离各数据中心的距离
SpreadsMat = repmat(Spreads,1,SamNum);
HiddenUnitOut = radbas(Distance./SpreadsMat); % 计算隐节点输出阵
HiddenUnitOutEx = [HiddenUnitOut' ones(SamNum,1)]'; % 考虑偏移
W2Ex = SamOut*pinv(HiddenUnitOutEx); % 求广义输出权值
W2 = W2Ex(:,1:ClusterNum); % 输出权值
B2 = W2Ex(:,ClusterNum+1); % 偏移
% 测试
TestDistance = dist(Centers',TestSamIn);
TestSpreadsMat = repmat(Spreads,1,TestSamNum);
TestHiddenUnitOut = radbas(TestDistance./TestSpreadsMat);
TestNNOut = W2*TestHiddenUnitOut+B2;
plot(TestSamIn,TestNNOut,'k-')
W2
B2
4.模糊神经网络算法(FNN)
模糊神经网络(Fuzzy Neural Network, FNN),神经网络与模糊系统的结合,在处理大规模的模糊应用问题方面将表现出优良效果。模糊神经网络本质是将模糊输入信号和模糊权值输入常规的神经网络。其结构上像神经网络,功能上是模糊系统。学习算法是模糊神经网络优化权系数的关键。
1.FNN算法特点
模糊神经网络虽然也是局部逼近网络,但是它是按照模糊系统模型建立的,网络中的各个结点及所有参数均有明显的物理意义,因此这些参数的初值可以根据系统或定性的知识来加以确定,然后利用上述的学习算法可以很快收敛到要求的输入输出关系,这是模糊神经网络比前面单纯的神经网络的优点所在。同时由于它具有神经网络的结构,因而参数的学习和调整比较容易,这是它比单纯的模糊逻辑系统的优点所在。
2.FNN算法结构
模糊神经网络将模糊系统和神经网络相结合,充分考虑了二者的互补性,集逻辑推理、语言计算、非线性动力学于一体,具有学习、联想、识别、自适应和模糊信息处理能力等功能。
本质: 就是将常规的神经网络输入模糊输入信号和模糊权值。
输入层: 模糊系统的输入信号
输出层: 模糊系统的输出信号
隐藏层: 隶属函数和模糊规则
利用神经网络的学习方法,根据输入输出的学习样本自动设计和调整模糊系统的设计参数,实现模糊系统的自学习和自适应功能。结构上像神经网络,功能上是模糊系统,这是目前研究和应用最多的一类模糊神经网络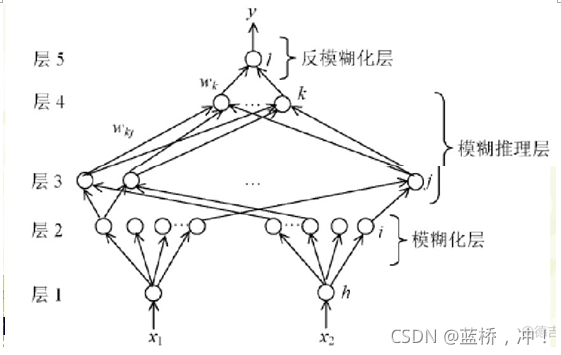
第1层:输入层,为精确值。节点个数为输入变量的个数。
第2层:输入变量的隶属函数层,实现输入变量的模糊化,x1有m个集合,x2有n个集合。
第3层:也称“与”层,该层节点个数为模糊规则数。该层每个节点只与第二层中m个节点中的一个和n个节点中的一个相连,共有m×n个节点,也就是有m×n条规则。
第4层:也称“或”层,节点数为输出变量模糊度划分的个数q。
该层与第三层的连接为全互连,连接权值为wkj ,其中
k=1.2…m×n
j=1.2…q
(权值代表了每条规则的置信度,训练中可调。)
第5层:清晰化层,节点数为输出变量的个数。该层与第四层的连接为全互连,该层将第四层各个节点的输出转换为输出变量的精确值。
第2层的隶属函数参数和3、4层间及4、5层间的连接权是可以调整的
学习算法是模糊神经网络优化权系数的关键。模糊神经网络的学习算法,大多来自神经网络,如BP算法、RBF算法等。
matlab实现神经网络:1.不使用神经网络工具箱实现BPnumberOfSample = 20; %输入样本数量%取测试样本数量等于输入(训练集)样本数量,因为输入样本(训练集)容量较少,否则一般必须用新鲜数据进行测试numberOfTe ...