python 使用tensorflow实现自编码Autoencoder
当你发现数据的维度太多怎么办!没关系,我们给它降维!
当你发现不会降维怎么办!没关系,来这里看看怎么autoencode
antoencoder简介
1、为什么要降维
随着社会的发展,可以利用人工智能解决的越来越多,人工智能所需要处理的问题也越来越复杂,作为神经网络的输入量,维度也越来越大,也就出现了当前所面临的“维度灾难”与“信息丰富、知识贫乏”的问题。
维度太多并不是一件优秀的事情,太多的维度同样会导致训练效率低,特征难以提取等问题,如果可以通过优秀的方法对特征进行提取,将会大大提高训练效率。
常见的降维方法有PCA(主成分分析)和LDA(线性判别分析,Fisher Linear Discriminant Analysis),二者的使用方法我会在今后的日子继续写BLOG进行阐明。
2、antoencoder的原理
如图是一个降维的神经网络的示意图,其可以将n维数据量降维2维数据量:
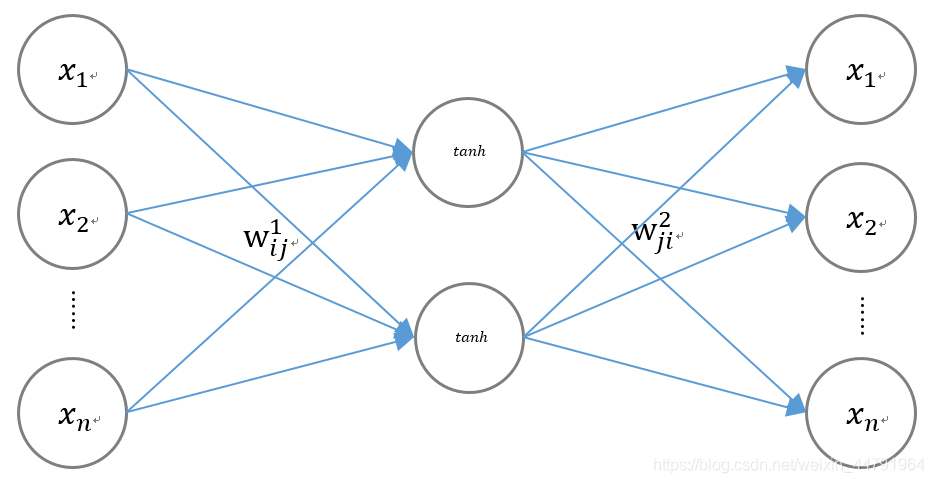
输入量与输出量都是数据原有的全部特征,我们利用tensorflow的optimizer对w1ij和w2ji进行优化。在优化的最后,w1ij就是我们将n维数据编码到2维的编码方式,w2ji就是我们将2维数据进行解码到n维数据的解码方式。
3、python中encode的实现
def encoder(x):
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['encoder_h3']),
biases['encoder_b3']))
layer_4 = tf.add(tf.matmul(layer_3, weights['encoder_h4']),
biases['encoder_b4'])
return layer_4
def decoder(x):
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['decoder_h3']),
biases['decoder_b3']))
layer_4 = tf.nn.sigmoid(tf.add(tf.matmul(layer_3, weights['decoder_h4']),
biases['decoder_b4']))
return layer_4
encoder_op = encoder(X)
decoder_op = decoder(encoder_op)
其中encode函数的输出就是编码后的结果。
全部代码
该例子为手写体识别例子,将784维缩小为2维,并且以图像的方式显示。
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data",one_hot = "true")
learning_rate = 0.01 #学习率
training_epochs = 10 #训练十次
batch_size = 256
display_step = 1
examples_to_show = 10
n_input = 784
X = tf.placeholder(tf.float32,[None,n_input])
#encode的过程分为4次,分别是784->128、128->64、64->10、10->2
n_hidden_1 = 128
n_hidden_2 = 64
n_hidden_3 = 10
n_hidden_4 = 2
weights = {
#这四个是用于encode的
'encoder_h1': tf.Variable(tf.truncated_normal([n_input, n_hidden_1],)),
'encoder_h2': tf.Variable(tf.truncated_normal([n_hidden_1, n_hidden_2],)),
'encoder_h3': tf.Variable(tf.truncated_normal([n_hidden_2, n_hidden_3],)),
'encoder_h4': tf.Variable(tf.truncated_normal([n_hidden_3, n_hidden_4],)),
#这四个是用于decode的
'decoder_h1': tf.Variable(tf.truncated_normal([n_hidden_4, n_hidden_3],)),
'decoder_h2': tf.Variable(tf.truncated_normal([n_hidden_3, n_hidden_2],)),
'decoder_h3': tf.Variable(tf.truncated_normal([n_hidden_2, n_hidden_1],)),
'decoder_h4': tf.Variable(tf.truncated_normal([n_hidden_1, n_input],)),
}
biases = {
#这四个是用于encode的
'encoder_b1': tf.Variable(tf.random_normal([n_hidden_1])),
'encoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'encoder_b3': tf.Variable(tf.random_normal([n_hidden_3])),
'encoder_b4': tf.Variable(tf.random_normal([n_hidden_4])),
#这四个是用于decode的
'decoder_b1': tf.Variable(tf.random_normal([n_hidden_3])),
'decoder_b2': tf.Variable(tf.random_normal([n_hidden_2])),
'decoder_b3': tf.Variable(tf.random_normal([n_hidden_1])),
'decoder_b4': tf.Variable(tf.random_normal([n_input])),
}
def encoder(x):
#encode函数,分为四步,layer4为编码后的结果
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['encoder_h1']),
biases['encoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['encoder_h2']),
biases['encoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['encoder_h3']),
biases['encoder_b3']))
layer_4 = tf.add(tf.matmul(layer_3, weights['encoder_h4']),
biases['encoder_b4'])
return layer_4
def decoder(x):
#decode函数,分为四步,layer4为解码后的结果
layer_1 = tf.nn.sigmoid(tf.add(tf.matmul(x, weights['decoder_h1']),
biases['decoder_b1']))
layer_2 = tf.nn.sigmoid(tf.add(tf.matmul(layer_1, weights['decoder_h2']),
biases['decoder_b2']))
layer_3 = tf.nn.sigmoid(tf.add(tf.matmul(layer_2, weights['decoder_h3']),
biases['decoder_b3']))
layer_4 = tf.nn.sigmoid(tf.add(tf.matmul(layer_3, weights['decoder_h4']),
biases['decoder_b4']))
return layer_4
encoder_op = encoder(X)
decoder_op = decoder(encoder_op)
#将编码再解码的结果与原始码对比,查看区别
y_pred = decoder_op
y_label = X
#比较特征损失情况
cost = tf.reduce_mean(tf.square(y_pred-y_label))
train = tf.train.AdamOptimizer(learning_rate).minimize(cost)
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
#每个世代进行total_batch次训练
total_batch = int(mnist.train.num_examples/batch_size)
for epoch in range(training_epochs):
for i in range(total_batch):
batch_xs,batch_ys = mnist.train.next_batch(batch_size)
_,c = sess.run([train,cost],feed_dict={X:batch_xs})
if epoch % display_step == 0:
print("Epoch :","%02d"%epoch,"cost =","%.4f"%c)
#利用test测试机进行测试
encoder_result = sess.run(encoder_op,feed_dict={X:mnist.test.images})
plt.scatter(encoder_result[:,0],encoder_result[:,1],c=np.argmax(mnist.test.labels,1),s=1)
plt.show()
实现结果为:
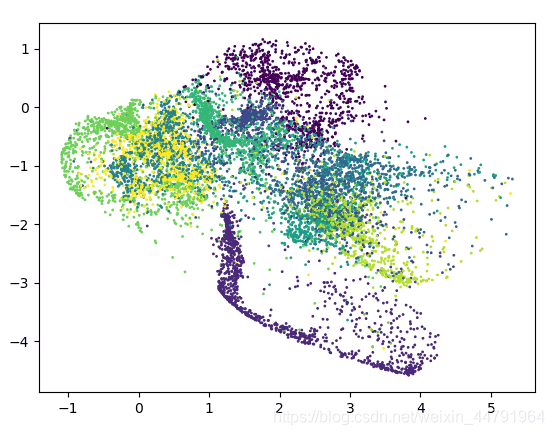
可以看到实验结果分为很多个区域块,基本可以识别。
以上就是python神经网络使用tensorflow实现自编码Autoencoder的详细内容,更多关于tensorflow自编码Autoencoder的资料请关注编程宝库其它相关文章!
Keras中保存与读取的重要函数1、model.savemodel.save用于保存模型,在保存模型前,首先要利用pip install安装h5py的模块,这个模块在Keras的模型保存与读 ...