Python无人监督学习:聚类
无监督机器学习算法没有任何主管提供任何形式的指导。这就是为什么它们与某些人称之为真正的人工智能紧密结合的原因。
在无人监督的学习中,没有正确的答案,也没有教师的指导。算法需要在数据中发现有趣的模式以供学习。
什么是聚类?
基本上,它是一种无监督学习方法和用于许多领域的统计数据分析的常用技术。聚类主要是将观察集划分为子集(称为聚类)的任务,使得同一聚类中的观察在一种意义上是相似的,并且它们与其他聚类中的观察不同。简单来说,我们可以说聚类的主要目标是在相似性和相异性的基础上对数据进行分组。
例如,下图显示了不同集群中的类似数据
聚类数据的算法
以下是一些用于聚类数据的常用算法
K-Means算法
K均值聚类算法是用于聚类数据的众所周知的算法之一。我们需要假设群集的数量已经知道。这也称为平面聚类。它是一种迭代聚类算法。此算法需要遵循以下步骤
第1步 - 我们需要指定所需的K个子组数。
步骤2 - 修复群集数量并将每个数据点随机分配给群集。或者换句话说,我们需要根据集群的数量对数据进行分类。
在此步骤中,应计算聚类质心。
由于这是一个迭代算法,我们需要在每次迭代时更新K质心的位置,直到我们找到全局最优或换句话说质心到达其最佳位置。
以下代码将有助于在Python中实现K-means聚类算法。我们将使用Scikit-learn模块。
让我们导入必要的包 -
import matplotlib.pyplot as plt import seaborn as sns; sns.set() import numpy as np from sklearn.cluster import KMeans
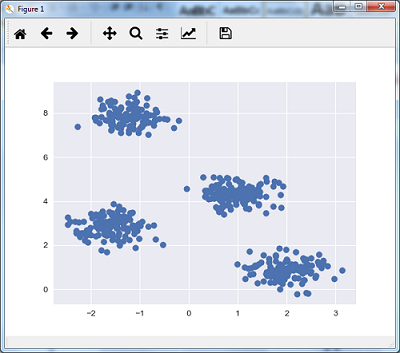
以下代码行将通过使用sklearn.dataset包中的make_blob来帮助生成包含四个blob的二维数据集。
from sklearn. datasets.samples_generator import make_blobs
X, y_true = make_blobs(n_samples = 500, centers = 4,
cluster_std = 0.40, random_state = 0)
我们可以使用以下代码可视化数据集
plt.scatter(X[:, 0], X[:, 1], s = 50); plt.show()
在这里,我们将kmeans初始化为KMeans算法,其中包含多少个簇(n_clusters)的必需参数。
kmeans = KMeans(n_clusters = 4)
我们需要用输入数据训练K-means模型。
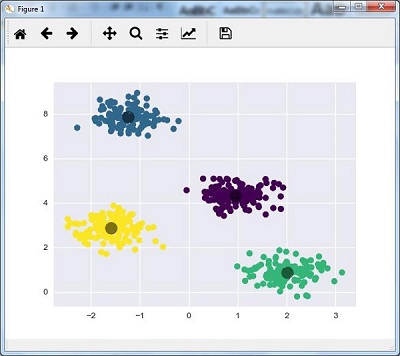
kmeans.fit(X) y_kmeans = kmeans.predict(X) plt.scatter(X[:, 0], X[:, 1], c = y_kmeans, s = 50, cmap = 'viridis') centers = kmeans.cluster_centers_
下面给出的代码将帮助我们根据我们的数据绘制和可视化机器的发现,并根据要找到的簇的数量来拟合。
plt.scatter(centers[:, 0], centers[:, 1], c = 'black', s = 200, alpha = 0.5); plt.show()
均值漂移算法
它是无监督学习中使用的另一种流行且强大的聚类算法。它没有做出任何假设,因此它是一个非参数算法。它也称为层次聚类或均值移位聚类分析。以下是此算法的基本步骤
- 首先,我们需要从分配给自己的集群的数据点开始。
- 现在,它计算质心并更新新质心的位置。
- 通过重复这个过程,我们移近群集的峰值,即朝向更高密度的区域。
- 该算法在质心不再移动的阶段停止。
在下面的代码的帮助下,我们在Python中实现了Mean Shift聚类算法。我们将使用Scikit-learn模块。
让我们导入必要的包
import numpy as np
from sklearn.cluster import MeanShift
import matplotlib.pyplot as plt
from matplotlib import style
style.use("ggplot")
以下代码将通过使用sklearn.dataset包中的make_blob来帮助生成包含四个blob的二维数据集。
from sklearn. datasets.samples_generator import make_blobs
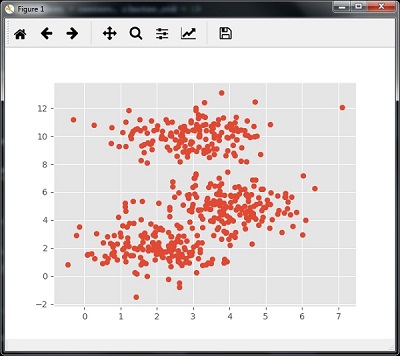
我们可以使用以下代码可视化数据集
centers = [[2,2],[4,5],[3,10]] X, _ = make_blobs(n_samples = 500, centers = centers, cluster_std = 1) plt.scatter(X[:,0],X[:,1]) plt.show()
现在,我们需要使用输入数据训练Mean Shift群集模型。
ms = MeanShift() ms.fit(X) labels = ms.labels_ cluster_centers = ms.cluster_centers_
以下代码将根据输入数据打印集群中心和预期的集群数
print(cluster_centers)
n_clusters_ = len(np.unique(labels))
print("Estimated clusters:", n_clusters_)
[[ 3.23005036 3.84771893]
[ 3.02057451 9.88928991]]
Estimated clusters: 2
下面给出的代码将帮助根据我们的数据绘制和可视化机器的发现,并根据要找到的聚类数量来拟合。
colors = 10*['r.','g.','b.','c.','k.','y.','m.'] for i in range(len(X)): plt.plot(X[i][0], X[i][1], colors[labels[i]], markersize = 10) plt.scatter(cluster_centers[:,0],cluster_centers[:,1], marker = "x",color = 'k', s = 150, linewidths = 5, zorder = 10) plt.show()

测量聚类性能
现实世界的数据并不是自然地组织成许多独特的集群。由于这个原因,想象和绘制推论并不容易。这就是我们需要测量聚类性能及其质量的原因。它可以在轮廓分析的帮助下完成。
剪影分析
该方法可用于通过测量簇之间的距离来检查聚类的质量。基本上,它提供了一种通过给出轮廓分数来评估诸如聚类数量之类的参数的方法。该分数是衡量一个群集中每个点与相邻群集中的点的接近程度的度量。
剪影分数分析
得分的范围为[-1,1]。以下是对这个分数的分析
- 分数+1 - 分数接近+1表示样本远离相邻群集。
- 得分为0 - 得分0表示样本处于或非常接近两个相邻聚类之间的决策边界。
- 分数-1 - 负分数表示样本已分配到错误的群集。
计算剪影分数
在本节中,我们将学习如何计算轮廓分数。
剪影分数可以使用以下公式计算
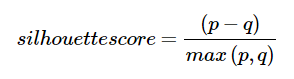
这里,p是到数据点不属于的最近集群中的点的平均距离。并且,q是到其自己的集群中所有点的平均集群内距离。
为了找到最佳簇数,我们需要通过从sklearn包导入metrics模块再次运行聚类算法。
在下面的示例中,我们将运行K-means聚类算法以查找最佳聚类数
如图所示导入必要的包
import matplotlib.pyplot as plt import seaborn as sns; sns.set() import numpy as np from sklearn.cluster import KMeans
用下面的代码的帮助下,我们将生成的二维数据集,包含四个斑点,通过使用make_blob从sklearn.dataset包。
from sklearn.datasets.samples_generator import make_blobs X, y_true = make_blobs(n_samples = 500, centers = 4, cluster_std = 0.40, random_state = 0)
初始化变量如图所示
scores = [] values = np.arange(2, 10)
我们需要通过所有值迭代K-means模型,并且还需要使用输入数据来训练它。
for num_clusters in values: kmeans = KMeans(init = 'k-means++', n_clusters = num_clusters, n_init = 10) kmeans.fit(X)
现在,使用欧几里德距离度量估计当前聚类模型的轮廓得分
score = metrics.silhouette_score(X, kmeans.labels_, metric = 'euclidean', sample_size = len(X))
以下代码行将有助于显示群集数量和Silhouette分数。
print("\nNumber of clusters =", num_clusters)
print("Silhouette score =", score)
scores.append(score)
您将收到以下输出
Number of clusters = 9
Silhouette score = 0.340391138371
num_clusters = np.argmax(scores) + values[0]
print('\nOptimal number of clusters =', num_clusters)
现在,最佳簇数的输出如下
Optimal number of clusters = 2
找到最近的邻居
如果我们想要建立诸如电影推荐系统之类的推荐系统,那么我们需要理解寻找最近邻居的概念。这是因为推荐系统利用了最近邻居的概念。
寻找最近邻居的概念可以被定义为从给定数据集中找到与输入点的最近点的过程。该KNN)K-最近邻居算法的主要用途是构建分类系统,该分类系统将输入数据点附近的数据点分类为各种类。
下面给出的Python代码有助于找到给定数据集的K最近邻居
导入必要的包,如下所示。在这里,我们使用sklearn包中的NearestNeighbors模块
import numpy as np import matplotlib.pyplot as plt from sklearn.neighbors import NearestNeighbors
现在让我们定义输入数据
A = np.array([[3.1, 2.3], [2.3, 4.2], [3.9, 3.5], [3.7, 6.4], [4.8, 1.9],
[8.3, 3.1], [5.2, 7.5], [4.8, 4.7], [3.5, 5.1], [4.4, 2.9],])
现在,我们需要定义最近的邻居
k = 3
我们还需要提供测试数据,从中找到最近的邻居
test_data = [3.3, 2.9]
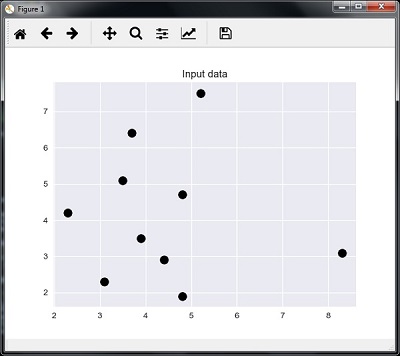
以下代码可以显示和绘制我们定义的输入数据
plt.figure()
plt.title('Input data')
plt.scatter(A[:,0], A[:,1], marker = 'o', s = 100, color = 'black')
现在,我们需要构建K最近邻。该对象也需要训练
knn_model = NearestNeighbors(n_neighbors = k, algorithm = 'auto').fit(X) distances, indices = knn_model.kneighbors([test_data])
现在,我们可以按如下方式打印K个最近邻居
print("\nK Nearest Neighbors:")
for rank, index in enumerate(indices[0][:k], start = 1):
print(str(rank) + " is", A[index])
我们可以将最近的邻居与测试数据点一起可视化
plt.figure()
plt.title('Nearest neighbors')
plt.scatter(A[:, 0], X[:, 1], marker = 'o', s = 100, color = 'k')
plt.scatter(A[indices][0][:][:, 0], A[indices][0][:][:, 1],
marker = 'o', s = 250, color = 'k', facecolors = 'none')
plt.scatter(test_data[0], test_data[1],
marker = 'x', s = 100, color = 'k')
plt.show()
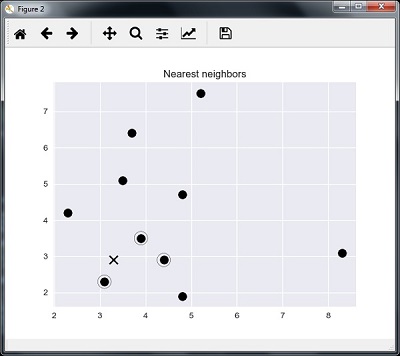
输出
K最近的邻居
1 is [ 3.1 2.3] 2 is [ 3.9 3.5] 3 is [ 4.4 2.9]
K-Nearest Neighbors Classifier
K-Nearest Neighbors(KNN)分类器是一种分类模型,它使用最近邻算法对给定数据点进行分类。我们在上一节中已经实现了KNN算法,现在我们将使用该算法构建KNN分类器。
KNN分类器的概念
K-最近邻分类的基本概念是找到与新样本距离最近的训练样本的预定数量,即'k',其必须被分类。新样本将从邻居本身获得他们的标签。KNN分类器具有固定的用户定义的常数,用于必须确定的邻居的数量。对于距离,标准欧几里德距离是最常见的选择。KNN分类器直接在学习的样本上工作,而不是创建学习规则。KNN算法是所有机器学习算法中最简单的算法之一。它在大量分类和回归问题中非常成功,例如字符识别或图像分析。
例
我们正在构建一个KNN分类器来识别数字。为此,我们将使用MNIST数据集。我们将在Jupyter Notebook中编写此代码。
导入必要的包,如下所示。
这里我们使用sklearn.neighbors包中的KNeighborsClassifier模块
from sklearn. datasets import * import pandas as pd %matplotlib inline from sklearn.neighbors import KNeighborsClassifier import matplotlib.pyplot as plt import numpy as np
以下代码将显示数字图像以验证我们要测试的图像
def Image_display(i): plt.imshow(digit['images'][i],cmap = 'Greys_r') plt.show()
现在,我们需要加载MNIST数据集。实际上总共有1797个图像,但我们使用前1600个图像作为训练样本,剩下的197个图像将用于测试目的。
digit = load_digits() digit_d = pd.DataFrame(digit['data'][0:1600])
现在,在显示图像时,我们可以看到输出如下 -
Image_display(0)
Image_display(0)
0的图像显示如下
Image_display(9)
9的图像显示如下 -
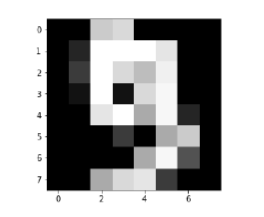
digit.keys()
现在,我们需要创建训练和测试数据集,并为KNN分类器提供测试数据集。
train_x = digit['data'][:1600] train_y = digit['target'][:1600] KNN = KNeighborsClassifier(20) KNN.fit(train_x,train_y)
以下输出将创建K最近邻分类器构造函数
KNeighborsClassifier(algorithm = 'auto', leaf_size = 30, metric = 'minkowski', metric_params = None, n_jobs = 1, n_neighbors = 20, p = 2, weights = 'uniform')
我们需要通过提供大于1600的任意数字来创建测试样本,这是训练样本。
test = np.array(digit['data'][1725]) test1 = test.reshape(1,-1) Image_display(1725)
Image_display(6)
6的图像显示如下
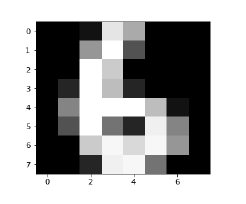
现在我们将预测测试数据如下
KNN.predict(test1)
上面的代码将生成以下输出
array([6])
现在,考虑以下
digit['target_names']
上面的代码将生成以下输出
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
Python自然语言处理:自然语言处理(NLP)是指使用诸如英语之类的自然语言与智能系统通信的AI方法。当您希望像机器人这样的智能系统按照您的指示执行,当您想要听取基于对话的临床专家系统的决定等时,需要处理自然语言。NLP领域涉及使计算机使 ...