R语言 用均值替换、回归插补和多重插补进行插补
用均值替换、回归插补及多重插补进行插补
# 设置工作空间
# 把“数据及程序”文件夹拷贝到F盘下,再用setwd设置工作空间
setwd("E:\\R_workspace\\R语言数据分析与挖掘实战\\chp4")
# 读取销售数据文件,提取标题行
inputfile <- read.csv('./data/catering_sale.csv', header = TRUE)
View(inputfile)
# 变换变量名
inputfile <- data.frame(sales = inputfile$'销量', date = inputfile$'日期')
View(inputfile)
# 数据截取
inputfile <- inputfile[5:16, ]
View(inputfile)
# 缺失数据的识别
is.na(inputfile) # 判断是否存在缺失
n <- sum(is.na(inputfile)) # 输出缺失值个数
n
# 异常值识别
par(mfrow = c(1, 2)) # 将绘图窗口划为1行两列,同时显示两图
dotchart(inputfile$sales) # 绘制单变量散点图
boxplot(inputfile$sales, horizontal = TRUE) # 绘制水平箱形图
# 异常数据处理
inputfile$sales[5] = NA # 将异常值处理成缺失值
fix(inputfile) # 表格形式呈现数据
# 缺失值的处理
inputfile$date <- as.numeric(inputfile$date) # 将日期转换成数值型变量
sub <- which(is.na(inputfile$sales)) # 识别缺失值所在行数
sub
# 将数据集分成完整数据和缺失数据两部分
inputfile1 <- inputfile[-sub, ]
inputfile2 <- inputfile[sub, ]
# 行删除法处理缺失,结果转存
result1 <- inputfile1
View(result1)
# 均值替换法处理缺失,结果转存
avg_sales <- mean(inputfile1$sales) # 求变量未缺失部分的均值
avg_sales
# 用均值替换缺失
inputfile2$sales <- rep(avg_sales,n)
# 并入完成插补的数据
result2 <- rbind(inputfile1, inputfile2)
View(result2)
# 回归插补法处理缺失,结果转存
# 回归模型拟合
# 注意:因变量~自变量
model <- lm(sales ~ date, data = inputfile1)
# 模型预测
inputfile2$sales <- predict(model, inputfile2)
result3 <- rbind(inputfile1, inputfile2)
# 多重插补法处理缺失,结果转存
library(lattice) # 调入函数包
library(MASS)
library(nnet)
library(mice) # 前三个包是mice的基础
# 4重插补,即生成4个无缺失数据集
imp <- mice(inputfile, m = 4)
# 选择插补模型
# inputfile为原始数据,有缺失
fit <- with(imp,lm(sales ~ date, data = inputfile))
# m重复完整数据分析结果池
pooled <- pool(fit)
summary(pooled)
result4 <- complete(imp, action = 3) # 选择第三个插补数据集作为结果
补充:R语言数据缺失值处理(随机森林,多重插补)
缺失值是指数据由于种种因素导致的数据不完整,可以分为机械原因和人为原因。对于缺失值我们通常采用以下几种方法来进行插补。
1.读取数据
通过read.csv函数导入文档,也可以用其他函数读入,如openxlsx::read.xlsx,read.table等。
head()查看数据前几行。
airquality <- read.csv(data.csv) head(airquality)
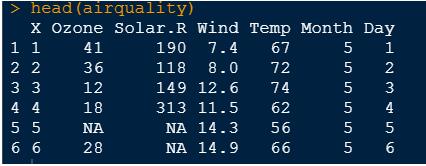
2.检查数据完整性
首先,summary()查看数据基本信息
summary(airairquality)
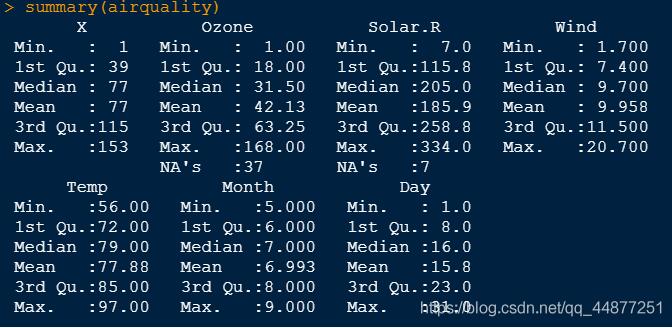
可以看到Ozone中存在缺失值NA
通过调用VIM::aggr()查看函数的缺失值(如果包安装较慢,可选用本地安装,链接已附需自行下载)
#install.packages(‘VIM') library(VIM) aggr(airquality)
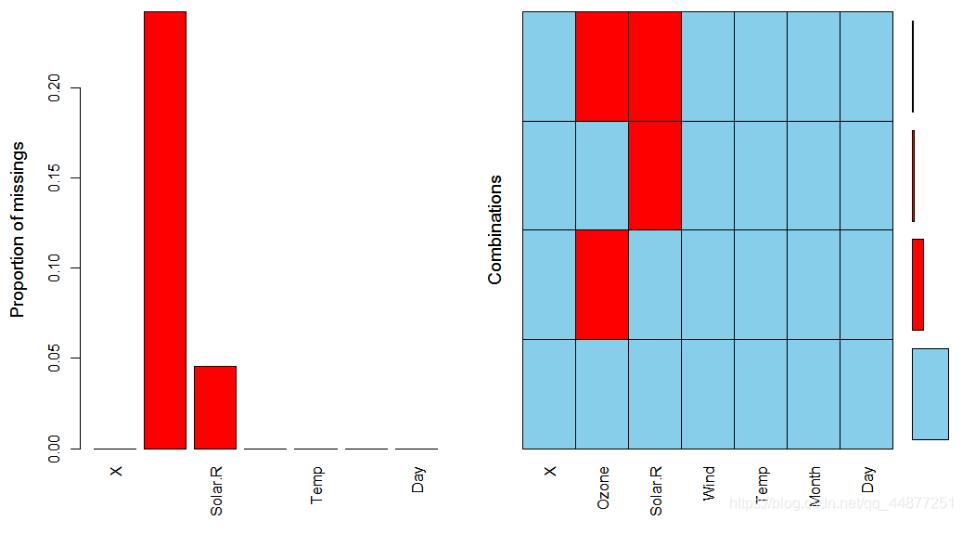
通过上图,可以看到Ozone和Solar.R存在缺失值。
3.缺失值填补
3.1简单处理填补
(1)删除缺失值
若样本中存在较少缺失值或缺失值比例较小不影响分析结果时,可选择直接将缺失值删除。
dat1 <- na.omit(airquality)
(2)平均值、中位数填补
若不能直接将缺失值删除也可选择平均值、众数、中位数等进行填补
#平均值填补
airquality$ Ozone[is.na(airquality$Ozone)] <- mean(airquality $ Ozone,na.rm=T)
#中位数填补
airquality$ Solar.R[is.na(airquality$ Solar.R)] <- median(airquality$ Solar.R,na.rm = T)
#计算缺失值个数,等于0 则不存在缺失值
sum(is.na(airquality))
#相邻均值填补
airquality <- read.csv(data.csv) #重新读入数据
for (i in 1:length(airquality$ Ozone)) {
airquality$ Ozone[i] <- ifelse(is.na(airquality$ Ozone[i]),
mean(c(airquality$ Ozone[i-1],airquality$ Ozone[i+1]),na.rm=T),
airquality$ Ozone[i])
}
3.2复杂处理填补
(1)K-近邻算法填补
基本思想:对于需要填补的观测值,先利用欧氏距离找到其邻近的K个观测,再将这K个邻近的值进行加权平均进行填补。
原始数据中存在多个缺失值,可以利用DMwR包中的knnImputation()函数进行填补
dat1 <- knnImputation(airquality[,c(1:4)],meth = ‘weighAvg',scale = T)
提取原始数据中的前4列进行填补,meth = 'weighAvg'指使用加权平均的方法进行填补,scale = T指在选取邻近值时,先对数据进行标准化。
aggr(dat1) #查看缺失值分布
(2)随机森林填补缺失值
接下来介绍一个新的填补方法C随机森林填补,随机森林是机器学习中一种常见的方法,以决策树为基分类的器的集成学习模型。
missForest包中missForest()函数可实现随机森林填补,ntree代表模型中的树的棵数,一般情况下,对于高维数据可选择较小的值(如100),以达到快速插补的效果;对于大数据集进行填补时,可能耗时比较多。
library(missForest) dat2 <- missForest(airquality,ntree = 100)
dat2中包含填补好的数据,可利用dat2$ximp查看填补后的值,
head(dat2$ximp) aggr(dat2$ximp)
同时,OOBerror表示袋外填补缺失的误差估计。
dat2$OOBerror

4.多重插补法
多重插补法是在一个缺失的数据集中生成一个完整的数据集,并利用蒙特卡洛的方法进行填补的一种重复模拟的方法。
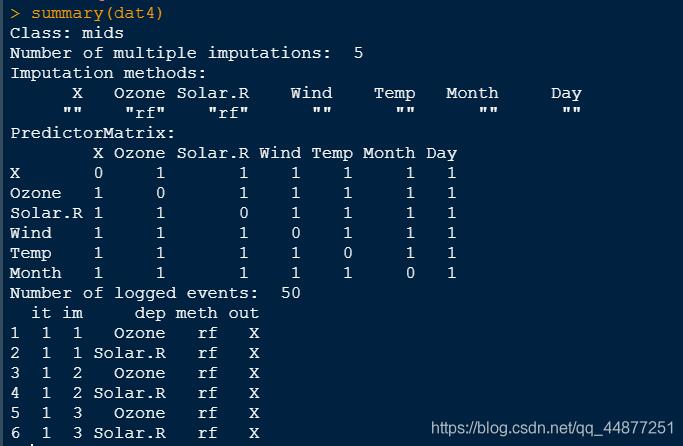
包mice中的mice()函数可实现对缺失数据的多重插补,原数据集中Ozone和Solar.R变量存在缺失,采用‘rf'法插补。
dat3 <- mice(airquality,m=5,method = ‘rf')
其中,m为生成完整数据集的个数,默认为5. method为插补参数的方法,‘norm.predict'、‘pmm'、‘rf'、‘norm'依次为回归预测法、平均值插补法、随机森林法和高斯线性回归法。
summary(dat3)
通过以下代码可查看填补的值
dat3$ imp$Solar.R
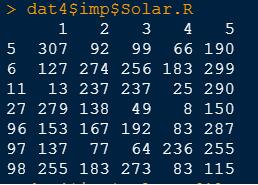
最后选择某一列(如1,2,3)填充到缺失数据集中即可形成完整的数据集.
以上为个人经验,希望能给大家一个参考,也希望大家多多支持编程宝库。如有错误或未考虑完全的地方,望不吝赐教。
在R语言中,par 函数可以设置图形边距,其中oma 参数设置outer margin, mar 参数设置margin,这些边距有什么不同呢,通过box函数可以直观的看到box 默认在当前图形绘制边框,第一个参数whi ...