Hadoop 大数据解决方案
传统方法
在这种方法中,企业将有一台计算机来存储和处理大数据。这里的数据将存储在RDBMS中,如Oracle数据库,MS SQL Server或DB2,并且可以编写复杂的软件与数据库进行交互,处理所需数据并将其呈现给用户进行分析。

局限性
这种方法适用于标准数据库服务器可以容纳的数据量较少的情况,或达到处理数据的处理器的限制的情况。但是当涉及到处理大量数据时,通过传统的数据库服务器来处理这些数据是一项非常乏味的任务。
Google的解决方案
Google使用一种名为MapReduce的算法解决了这个问题。该算法将任务分成小部分,并将这些部分分配给通过网络连接的许多计算机,并收集结果以形成最终结果数据集。
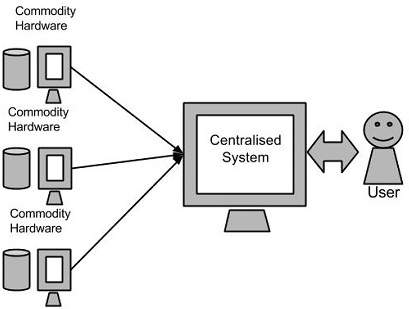
上图显示了各种商品硬件,可能是单个CPU机器或更高容量的服务器。
Hadoop的
道格切割,迈克Cafarella和团队采取谷歌提供的解决方案,并于2005年开始一个名为HADOOP的开源项目,道格命名为他的儿子的玩具大象。现在,Apache Hadoop是Apache Software Foundation的注册商标。
Hadoop使用MapReduce算法运行应用程序,其中数据在不同CPU节点上并行处理。简而言之,Hadoop框架足以开发能够在计算机集群上运行的应用程序,并且可以对大量数据执行完整的统计分析。
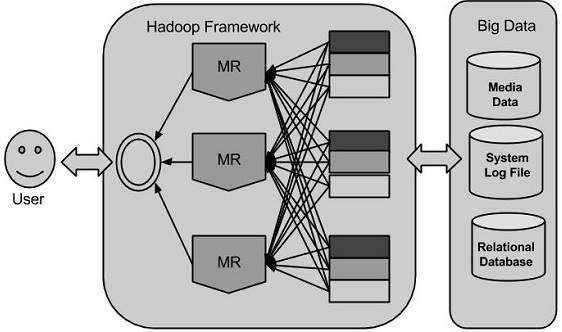
Hadoop是一个用java编写的Apache开放源代码框架,它允许使用简单的编程模型在计算机集群中分布式处理大型数据集。Hadoop框架式应用程序在跨计算机群集提供分布式存储和计算的环境中工作。Hadoop旨在从单个服 ...