Apache Pig Group Operator
Apache Pig GROUP 运算符用于将数据分组为一个或多个关系。它将包含相似组键的元组分组。如果组键有多个字段,则将其视为元组,否则将与组键的类型相同。结果,它提供了一个每组包含一个元组的关系。
组运算符示例
在此示例中,我们将给定的数据分组姓氏的。
执行Group Operator的步骤
- 在您的本地机器上创建一个文本文件并在其中写入一些文本。
$ nano piginput2.txt
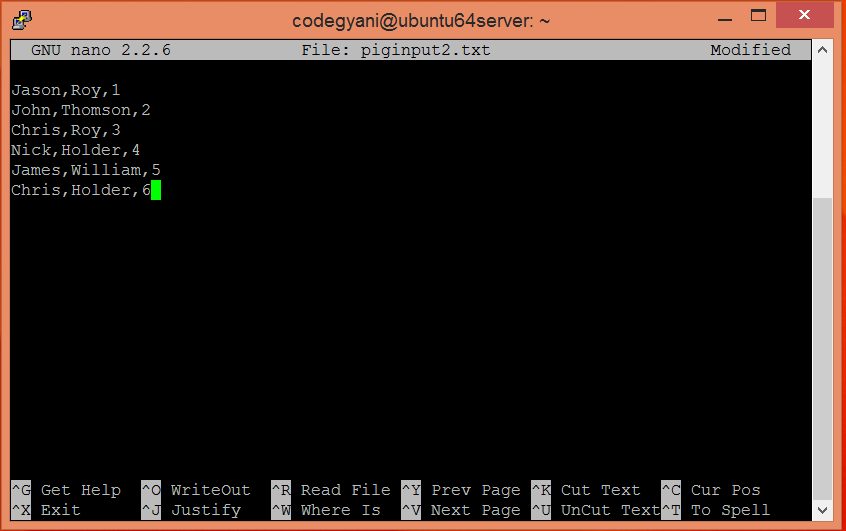
- 检查 piginput2.txt 文件中写入的文本。
$ cat piginput2.txt
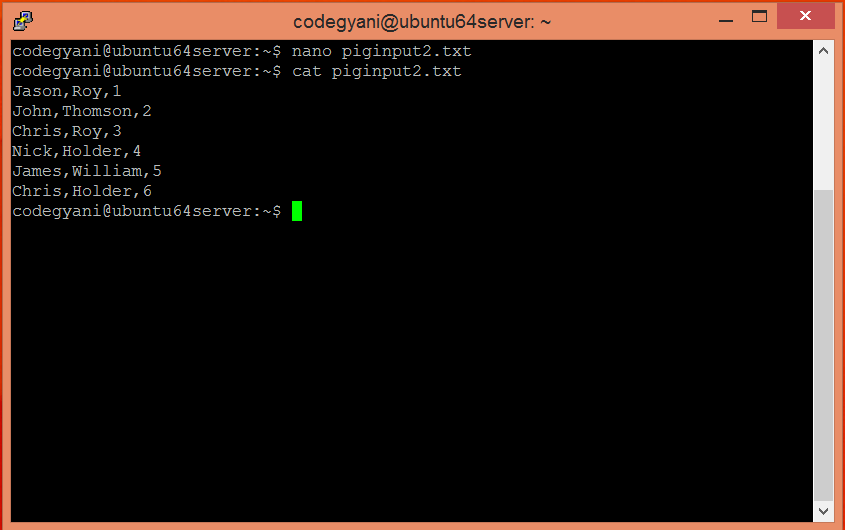
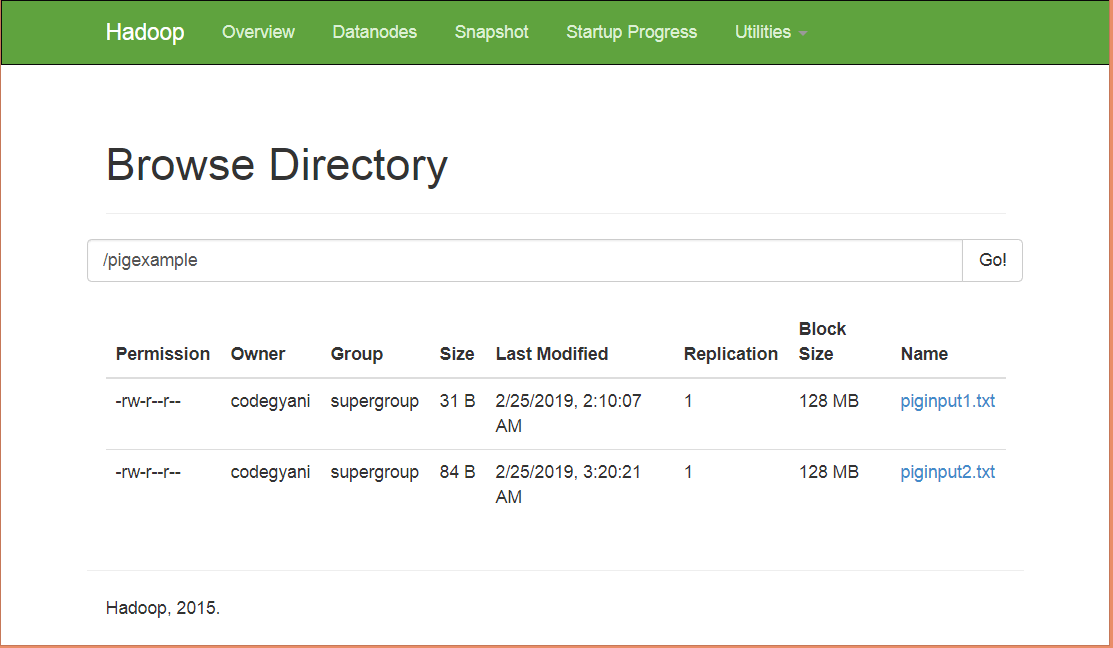
- 上传 HDFS 上指定目录下的 piginput2.txt 文件。
$ hdfs dfs-put /home/codegyani/piginput2.txt /pigexample
- 开启猪 MapReduce 运行模式。
$ pig
- 将数据加载到包中。
grunt> A = LOAD '/pigexample/piginput2.txt' USING PigStorage(',') AS (fname:chararray,l_name:chararray,id:int);
- 现在执行并验证数据。
grunt> DUMP A;
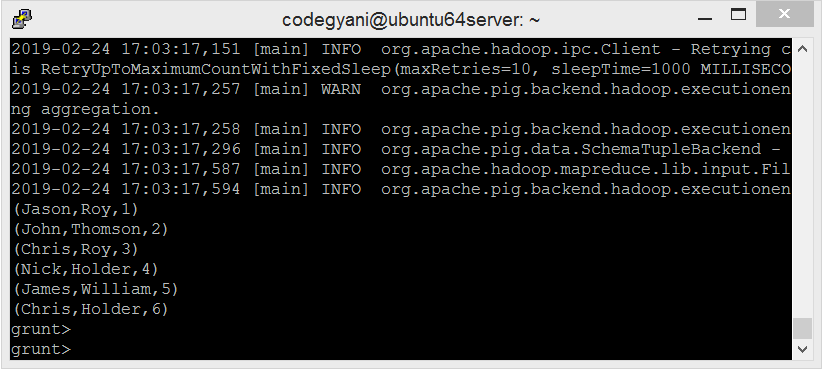
- 让我们根据 l_name 对数据进行分组。
grunt> groupbylname = group A by l_name ;
- 现在,执行并验证数据。
grunt> DUMP groupbylname;
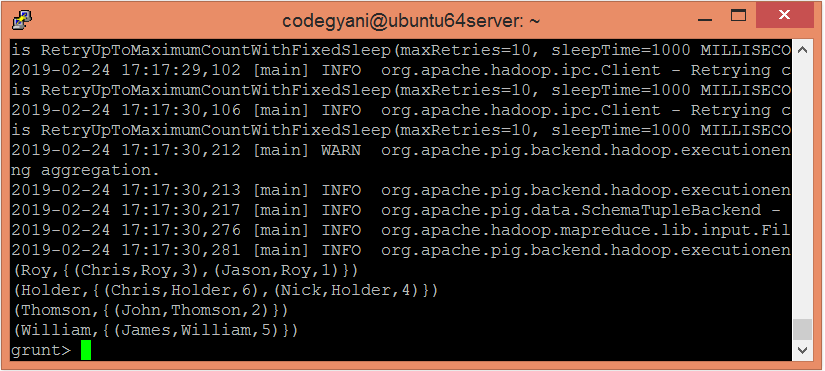
在这里,我们得到了想要的输出。
Apache Pig LIMIT 运算符用于限制输出元组的数量。但是,如果指定输出元组的限制等于或大于存在的元组数,则返回关系中的所有元组。 LIMIT 运算符示例在这个例子中,我们只返回 ...