Pandas 数据结构 - Series
Pandas Series 代表表格中的一个列(column),类似于一维数组,可以保存任何数据类型。
Series 由索引(index)和列组成,函数如下:
pandas.Series( data, index, dtype, name, copy)
参数说明:
- data:一组数据(ndarray 类型)。
- index:数据索引标签,如果不指定,默认从 0 开始。
- dtype:数据类型,默认会自己判断。
- name:设置名称。
- copy:拷贝数据,默认为 False。
创建一个简单的 Series 范例:
import pandas as pd a = [1, 2, 3] myvar = pd.Series(a) print(myvar)
输出结果如下:
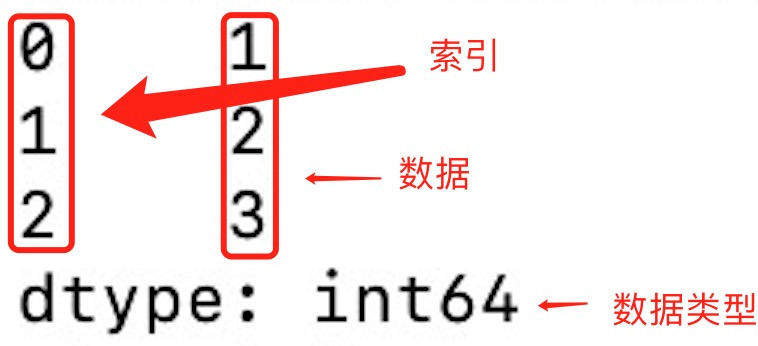
从上图可知,如果没有指定索引,索引值就从 0 开始,我们可以根据索引值读取数据:
import pandas as pd a = [1, 2, 3] myvar = pd.Series(a) print(myvar[1])
输出结果如下:
2
我们可以指定索引值,如下范例:
import pandas as pd a = ["Google", "Codebaoku", "Wiki"] myvar = pd.Series(a, index = ["x", "y", "z"]) print(myvar)
输出结果如下:

根据索引值读取数据:
import pandas as pd a = ["Google", "Codebaoku", "Wiki"] myvar = pd.Series(a, index = ["x", "y", "z"]) print(myvar["y"])
输出结果如下:
Codebaoku
我们也可以使用 key/value 对象,类似字典来创建 Series:
import pandas as pd
sites = {1: "Google", 2: "Codebaoku", 3: "Wiki"}
myvar = pd.Series(sites)
print(myvar)
输出结果如下:

从上图可知,字典的 key 变成了索引值。
如果我们只需要字典中的一部分数据,只需要指定需要数据的索引即可,如下范例:
import pandas as pd
sites = {1: "Google", 2: "Codebaoku", 3: "Wiki"}
myvar = pd.Series(sites, index = [1, 2])
print(myvar)
输出结果如下:

设置 Series 名称参数:
import pandas as pd
sites = {1: "Google", 2: "Codebaoku", 3: "Wiki"}
myvar = pd.Series(sites, index = [1, 2], name="CODEBAOKU-Series-TEST" )
print(myvar)

Pandas 数据结构 DataFrame:DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)。