微服务超时如何传递
为什么需要超时控制?
很多连锁故障的场景下的一个常见问题是服务器正在消耗大量资源处理那些早已经超过客户端截止时间的请求,这样的结果是,服务器消耗大量资源没有做任何有价值的工作,回复已经超时的请求是没有任何意义的。
超时控制可以说是保证服务稳定性的一道重要的防线,它的本质是快速失败(fail fast),良好的超时控制策略可以尽快清空高延迟的请求,尽快释放资源避免请求的堆积。
服务间超时传递
如果一个请求有多个阶段,比如由一系列 RPC 调用组成,那么我们的服务应该在每个阶段开始前检查截止时间以避免做无用功,也就是要检查是否还有足够的剩余时间处理请求。
一个常见的错误实现方式是在每个 RPC 服务设置一个固定的超时时间,我们应该在每个服务间传递超时时间,超时时间可以在服务调用的最上层设置,由初始请求触发的整个 RPC 树会设置同样的绝对截止时间。例如,在服务请求的最上层设置超时时间为3s,服务A请求服务B,服务B执行耗时为1s,服务B再请求服务C这时超时时间剩余2s,服务C执行耗时为1s,这时服务C再请求服务D,服务D执行耗时为500ms,以此类推,理想情况下在整个调用链里都采用相同的超时传递机制。
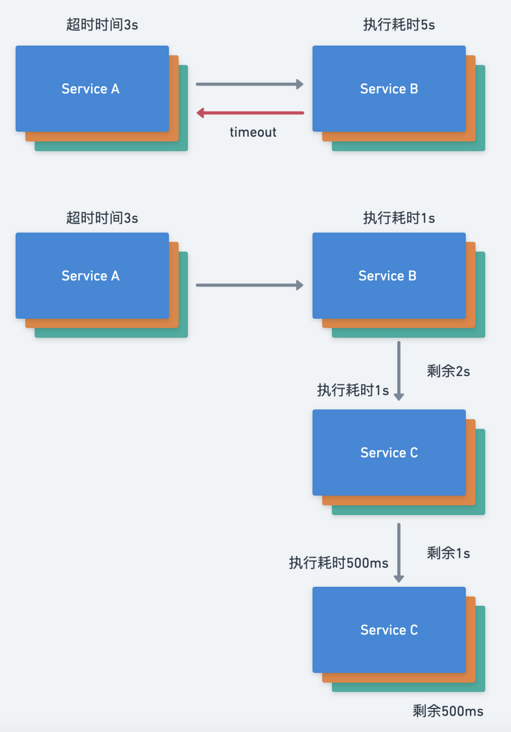
如果不采用超时传递机制,那么就会出现如下情况:
- 服务A给服务B发送一个请求,设置的超时时间为3s
- 服务B处理请求耗时为2s,并且继续请求服务C
- 如果使用了超时传递那么服务C的超时时间应该为1s,但这里没有采用超时传递所以超时时间为在配置中写死的3s
- 服务C继续执行耗时为2s,其实这时候最上层设置的超时时间已截止,如下的请求无意义
- 继续请求服务D
如果服务B采用了超时传递机制,那么在服务C就应该立刻放弃该请求,因为已经到了截止时间,客户端可能已经报错。我们在设置超时传递的时候一般会将传递出去的截止时间减少一点,比如100毫秒,以便将网络传输时间和客户端收到回复之后的处理时间考虑在内。
进程内超时传递
不光服务间需要超时传递进程内同样需要进行超时传递,比如在一个进程内串行的调用了Mysql、Redis和服务B,设置总的请求时间为3s,请求Mysql耗时1s后再次请求Redis这时的超时时间为2s,Redis执行耗时500ms再请求服务B这时候超时时间为1.5s,因为我们的每个中间件或者服务都会在配置文件中设置一个固定的超时时间,我们需要取剩余时间和设置时间中的最小值。
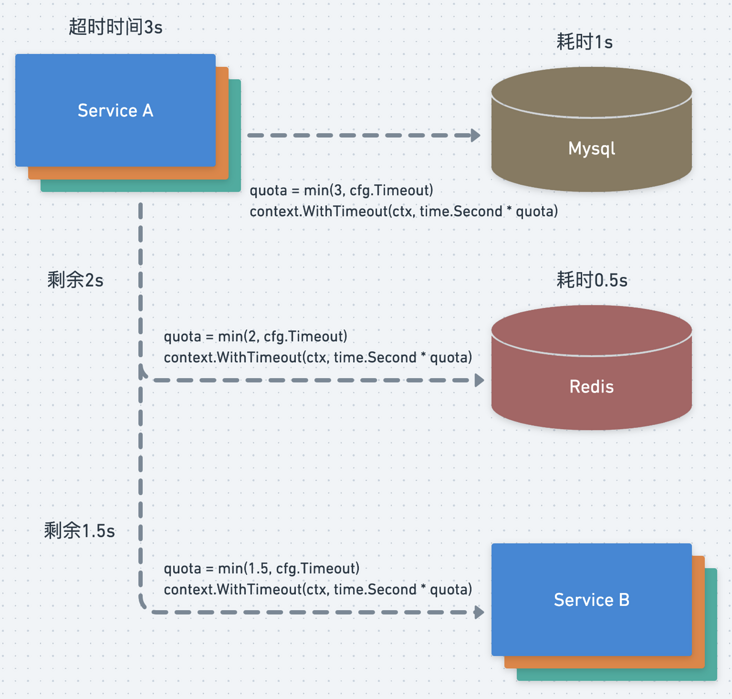
context实现超时传递
context原理非常简单,但功能却非常强大,go的标准库也都已实现了对context的支持,各种开源的框架也实现了对context的支持,context已然成为了标准,超时传递也依赖context来实现。
我们一般在服务的最上层通过设置初始context进行超时控制传递,比如设置超时时间为3s
ctx, cancel := context.WithTimeout(context.Background(), time.Second*3) defer cancel()
当进行context传递的时候,比如上图中请求Redis,那么通过如下方式获取剩余时间,然后对比Redis设置的超时时间取较小的时间
dl, ok := ctx.Deadline()
timeout := time.Now().Add(time.Second * 3)
if ok := dl.Before(timeout); ok {
timeout = dl
}服务间超时传递主要是指 RPC 调用时候的超时传递,对于 gRPC 来说并不需要要我们做额外的处理,gRPC 本身就支持超时传递,原理和上面差不多,是通过 metadata 进行传递,最终会被转化为 grpc-timeout 的值,如下代码所示 grpc-go/internal/transport/handler_server.go:79
if v := r.Header.Get("grpc-timeout"); v != "" {
to, err := decodeTimeout(v)
if err != nil {
return nil, status.Errorf(codes.Internal, "malformed time-out: %v", err)
}
st.timeoutSet = true
st.timeout = to
}超时传递是保证服务稳定性的一道重要防线,原理和实现都非常简单,你们的框架中实现了超时传递了吗?如果没有的话就赶紧动起手来吧。
水印的实现方案前端水印这个需求其实是一直存在的,最高频的场景是公司内部系统防止信息泄漏。如果实现放在前端,主流的实现方法分为以下两类:SVG / PNG 等图片结合 CSS background 属性Canvas比 ...