以太坊源码解读(8)以太坊P2P模块——节点发现和K-桶维护
回顾一下,前面说到以太坊分布式网络采用了Kademlia协议,它的特点是:
1、采用了二叉树的拓扑结构;
2、每个节点都对整树进行拆分,分成n棵子树;
3、从每棵树中取K个节点,构成“k-桶”,每个节点控制着n个k-桶;
4、节点的距离是通过异或的二进制运算得到的;
5、k桶中的节点不是固定不变的,而是不断刷新变化的。
下面,我们来看看Kademlia协议在以太坊中的具体实现。
一、以太坊的k桶
以太坊的k值是16,也就是说每个k桶包含16个节点,一共256个k桶。K桶中记录了节点的NodeId,distance,endpoint,ip等信息,按照与target节点的距离进行排序。
| distance 0:[2^0, 2^1) | node0 | node1 | node2 | ... | node15 |
| distance 1:[2^1, 2^2) | node0 | node1 | node2 | ... | node15 |
| distance 2:[2^2, 2^3) | node0 | node1 | node2 | ... | node15 |
| distance 3:[2^3, 2^4) | node0 | node1 | node2 | ... | node15 |
| ... | node0 | node1 | node2 | ... | node15 |
| distance 255:[2^255, 2^256) | node0 | node1 | node2 | ... | node15 |
这个表在源码里为Table对象(p2p/discover/table.go):
type Table struct {
mutex sync.Mutex // protects buckets, bucket content, nursery, rand
buckets [nBuckets]*bucket // index of known nodes by distance
nursery []*Node // bootstrap nodes
rand *mrand.Rand // source of randomness, periodically reseeded
ips netutil.DistinctNetSet
db *nodeDB // database of known nodes
refreshReq chan chan struct{}
initDone chan struct{}
closeReq chan struct{}
closed chan struct{}
nodeAddedHook func(*Node) // for testing
net transport
self *Node // metadata of the local node
}
这里有几项是比较重要的:
1)buckets 类型是[nBuckets]*bucket,可以看到这是一个数组,一个bucket就是一个K-桶,一共256个bucket;
2)nursery 信任的种子节点,一个节点启动的时候首先最多能够连接35个种子节点,其中5个是由以太坊官方提供的,另外30个是从数据库里取的;
3)db 以太坊中有两个数据库实例,一个是用来储存区块链,另一个用来储存p2p的节点。
4)refreshReq 刷新K桶事件的管道,其他节点或者其他应用场景可以通过这个管道强制刷新该节点的k桶。
二、table对象的相关方法
1、newTable()新建table
task1:根据外部或默认参数初始化Table类
task2:加载种子节点
task3:启动数据库刷新go程
task4:启动事件监听go程
func newTable(t transport, ourID NodeID, ourAddr *net.UDPAddr, nodeDBPath string, bootnodes []*Node)
(*Table, error) {
// If no node database was given, use an in-memory one
db, err := newNodeDB(nodeDBPath, nodeDBVersion, ourID)
if err != nil {
return nil, err
}
// 初始化Table类
tab := &Table{
net: t,
db: db,
self: NewNode(ourID, ourAddr.IP, uint16(ourAddr.Port), uint16(ourAddr.Port)),
refreshReq: make(chan chan struct{}),
initDone: make(chan struct{}),
closeReq: make(chan struct{}),
closed: make(chan struct{}),
rand: mrand.New(mrand.NewSource(0)),
ips: netutil.DistinctNetSet{Subnet: tableSubnet, Limit: tableIPLimit},
}
// 加载种子节点
// 首先,初始化K桶
if err := tab.setFallbackNodes(bootnodes); err != nil {
return nil, err
}
for i := range tab.buckets {
tab.buckets[i] = &bucket{
ips: netutil.DistinctNetSet{Subnet: bucketSubnet, Limit: bucketIPLimit},
}
}
tab.seedRand()
tab.loadSeedNodes() //从table.buckets中随机取30个节点加载种子节点到相应的bucket
// 启动刷新数据库的go程
tab.db.ensureExpirer()
// 事件监听go程
go tab.loop()
return tab, nil
}
2、加载种子节点 loadSeedNodes()
func (tab *Table) loadSeedNodes() {
seeds := tab.db.querySeeds(seedCount, seedMaxAge)
seeds = append(seeds, tab.nursery...)
for i := range seeds {
seed := seeds[i]
age := log.Lazy{Fn: func() interface{} { return time.Since(tab.db.lastPongReceived(seed.ID)) }}
log.Debug("Found seed node in database", "id", seed.ID, "addr", seed.addr(), "age", age)
tab.add(seed)
}
}
首先是从数据库里随机选取30个节点(seedCount),然后使用table.add()方法将每个节点加载到相应的bucket中。
func (tab *Table) add(n *Node) {
tab.mutex.Lock()
defer tab.mutex.Unlock()
b := tab.bucket(n.sha)
if !tab.bumpOrAdd(b, n) {
// Node is not in table. Add it to the replacement list.
tab.addReplacement(b, n)
}
}
这里的添加不是直接添加,我们可以看到bucket的结构中有一个replacement列表,当entries是满的时候,新找到的节点不是直接抛弃,而是放到replacement列表中。
type bucket struct {
entries []*Node // live entries, sorted by time of last contact
replacements []*Node // recently seen nodes to be used if revalidation fails
ips netutil.DistinctNetSet
}
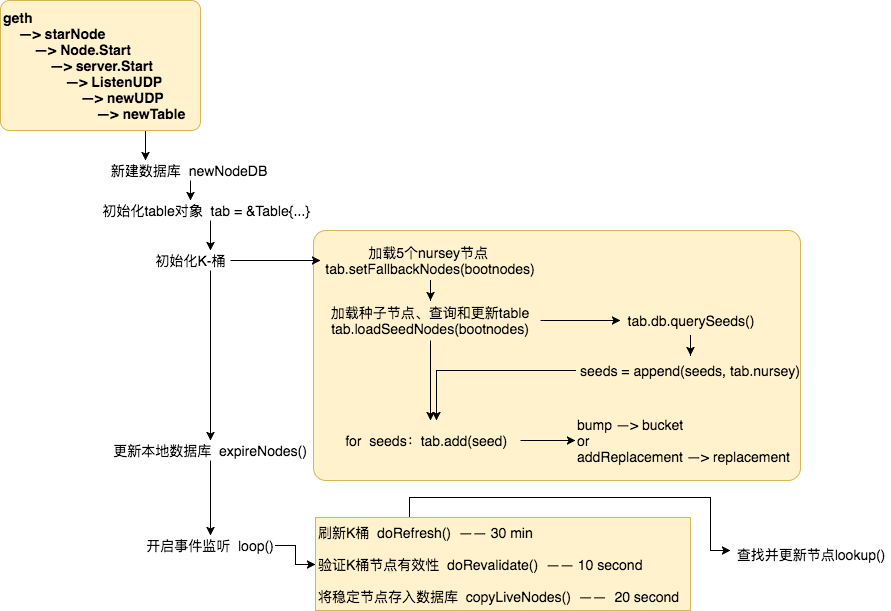
我们来总结一下k-桶初始化的过程:
1、先新建table对象,连接本地database,如果本地没有database,则先新建一个空的database;
2、初始化K-桶,先获得k-桶信息的源节点:
a. 通过setFallbackNodes(bootnodes)来获得5个nursey节点;
b. 通过tab.loadSeedNodes()——>tab.db.querySeeds()来从本地database获得最多30个节点;
3、把上面的节点存入seeds,进行for循环;
4、在循环内执行tab.add(seed),计算seed节点与本节点的距离,选择相应距离的bucket。如果bucket不满,则用bump()存入bucket;如果bucket已满,则放入replacements。
3、刷新数据库 expireNodes()
实际上是要定期(1小时,nodeDBCleanupCycle = time.Hour)删除数据库中过期的节点。什么是过期的节点?在discovery/database.go中定义了nodeDBNodeExpiration = 24*time.Hour,即只有24小时之内ping过的节点才能得以保留。
func (db *nodeDB) expireNodes() error {
threshold := time.Now().Add(-nodeDBNodeExpiration)
// Find discovered nodes that are older than the allowance
it := db.lvl.NewIterator(nil, nil)
defer it.Release()
for it.Next() {
// Skip the item if not a discovery node
id, field := splitKey(it.Key())
if field != nodeDBDiscoverRoot {
continue
}
// Skip the node if not expired yet (and not self)
if !bytes.Equal(id[:], db.self[:]) {
if seen := db.lastPongReceived(id); seen.After(threshold) {
continue
}
}
// Otherwise delete all associated information
db.deleteNode(id)
}
return nil
}
4、事件监听 loop()
// loop schedules refresh, revalidate runs and coordinates shutdown.
func (tab *Table) loop() {
var (
revalidate = time.NewTimer(tab.nextRevalidateTime()) // 验证节点是否可以ping通的时间通道
refresh = time.NewTicker(refreshInterval)
copyNodes = time.NewTicker(copyNodesInterval)
revalidateDone = make(chan struct{})
refreshDone = make(chan struct{}) // where doRefresh reports completion
waiting = []chan struct{}{tab.initDone} // holds waiting callers while doRefresh runs
)
defer refresh.Stop()
defer revalidate.Stop()
defer copyNodes.Stop()
// doRefresh用于执行lookup以保证k-桶是满的状态
go tab.doRefresh(refreshDone)
loop:
for {
select {
case <-refresh.C: // 定时刷新k桶事件,refreshInterval=30 min
tab.seedRand()
if refreshDone == nil {
refreshDone = make(chan struct{})
go tab.doRefresh(refreshDone)
}
case req := <-tab.refreshReq: // 刷新k桶的请求事件
waiting = append(waiting, req)
if refreshDone == nil {
refreshDone = make(chan struct{})
go tab.doRefresh(refreshDone)
}
case <-refreshDone:
for _, ch := range waiting {
close(ch)
}
waiting, refreshDone = nil, nil
case <-revalidate.C: // 验证k桶节点有效性,10 second
go tab.doRevalidate(revalidateDone)
case <-revalidateDone:
revalidate.Reset(tab.nextRevalidateTime())
case <-copyNodes.C: // 定时(30秒)将节点存入数据库,如果某个节点在k桶中存在超过5分钟,则认为它是一个稳定的节点
go tab.copyLiveNodes()
case <-tab.closeReq:
break loop
}
}
if tab.net != nil {
tab.net.close()
}
if refreshDone != nil {
<-refreshDone
}
for _, ch := range waiting {
close(ch)
}
tab.db.close()
close(tab.closed)
}
通过这个函数,我们看到我们的table以及k-桶是如何维护的:
1、每30分钟自动刷新k-桶(刷新k-桶可以补充或保持table是满的状态,刚初始化的table可能并不是满的,需要不断的补充和更新);
2、每10秒钟就去验证k-桶中的节点是否可以ping通;
3、每30秒就将k-桶中存在超过5分钟的节点存入本地数据库,视作稳定节点;
三、节点的查找doRefresh()、lookup()
1、doRefresh()
// doRefresh通过lookup()去查找一个随机的节点来保持bucket满载。
func (tab *Table) doRefresh(done chan struct{}) {
defer close(done)
// 加载节点,这些节点在最近一次看见时依然是活动的
tab.loadSeedNodes()
// 先用自己的节点ID,运行lookup来发现邻居节点
tab.lookup(tab.self.ID, false)
for i := 0; i < 3; i++ {
var target NodeID
// 随机一个target,进行lookup
crand.Read(target[:])
tab.lookup(target, false)
}
}
2、lookup函数
task1:从k桶中查找16个离target最近的节点,保存到result切片中;
task2:节点发现主循环(使用上一步中查找到的节点进行挨个询问最近的节点,更新result,保证result中的16个节点是最近的)
流程图
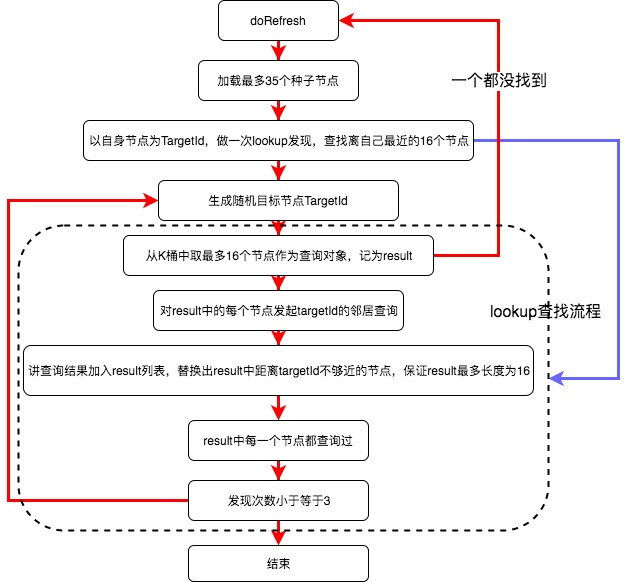
func (tab *Table) lookup(targetID NodeID, refreshIfEmpty bool) []*Node {
var (
target = crypto.Keccak256Hash(targetID[:])
asked = make(map[NodeID]bool) // 被访问过并接收到返回result切片的节点
seen = make(map[NodeID]bool) // 在result切片中但还没有访问的节点
reply = make(chan []*Node, alpha)
pendingQueries = 0
result *nodesByDistance
)
// 不需要询问自己,放在asked里就不用再访问
asked[tab.self.ID] = true
// ---------------------------------------------------------
// task1:从k桶中查找16个离targetId最近的点
// ---------------------------------------------------------
for {
tab.mutex.Lock()
// 初始化result切片,从k桶中最多取离目标最近的16个非初始节点
// closest采用最笨的办法,就是遍历table中的每一个节点,比较距离
result = tab.closest(target, bucketSize)
tab.mutex.Unlock()
// 如果从k桶中获取的节点数量大于0,或者上一次循环没有获取到初始节点,直接退出本次lookup
if len(result.entries) > 0 || !refreshIfEmpty {
break
}
// 如果一个都没找到,则发送刷新事件,从数据库中重新加载种子节点
<-tab.refresh()
refreshIfEmpty = false
}
// --------------------------------------------------------
// task2:对result中16个节点进行邻近节点查询
// 执行至此,说明result中不为空
// --------------------------------------------------------
for {
// 并发查询,同时最多3个goroutine并发请求(通过pendingQueries参数进行控制)
for i := 0; i < len(result.entries) && pendingQueries < alpha; i++ {
n := result.entries[i]
if !asked[n.ID] { // 只有未查询过的才能查询
asked[n.ID] = true
pendingQueries++
go tab.findnode(n, targetID, reply)
}
}
// 如果没有goroutine在请求,说明result中的节点都是最新的,且都询问过
if pendingQueries == 0 {
// we have asked all closest nodes, stop the search
break
}
// 上面启动的3个goroutine返回值为reply,检查如果reply非空且没有seen过
for _, n := range <-reply {
if n != nil && !seen[n.ID] {
seen[n.ID] = true
// push函数将节点放入result中,保证result数量不超过16
result.push(n, bucketSize)
}
}
// 到这里说明某个节点返回了结果,pendingQueries减少后又可以启动新的go程
pendingQueries--
}
return result.entries
}
看到这里,我们发现lookup只返回了一个result.entries,但是这些新找到的节点如何更新到K桶里呢?原来在lookup执行的过程中,就开启了go程,执行tab.findnode(),这个函数直接将找到的节点add进了K桶中。
func (tab *Table) findnode(n *Node, targetID NodeID, reply chan<- []*Node) {
// 查找失败的节点会储存在本地数据库中
fails := tab.db.findFails(n.ID)
r, err := tab.net.findnode(n.ID, n.addr(), targetID)
if err != nil || len(r) == 0 {
fails++
tab.db.updateFindFails(n.ID, fails)
log.Trace("Findnode failed", "id", n.ID, "failcount", fails, "err", err)
// 如果有5次以上fails,该节点会被抛弃,从表中删除
if fails >= maxFindnodeFailures {
log.Trace("Too many findnode failures, dropping", "id", n.ID, "failcount", fails)
tab.delete(n)
}
} else if fails > 0 {
tab.db.updateFindFails(n.ID, fails-1)
}
// Grab as many nodes as possible. Some of them might not be alive anymore, but we'll
// just remove those again during revalidation.
for _, n := range r {
tab.add(n)
}
reply <- r
}
所以上面提到的k-桶的维护中每30分钟就要刷新k桶,即调用doRefresh(),doRefresh首先对自身的节点查询,更新了最近的16个节点,然后又对随机的节点进行lookup查询,更新了相应k-桶中的16个节点。
一张图来回顾一下整个table新建和维护的过程:
四、节点查找的通信协议
节点的查找是基于UDP的通信协议:
| 分类 | 功能描述 | 构成 |
| PING | 探测一个节点,判断是否在线 | type ping struct {
Version uint
From, To rpcEndpoint
Expiration uint64
Rest []rlp.RawValue `rlp:"tail"`
} |
| PONG | PING命令响应 | type pong struct {
To rpcEndpoint
ReplyTok []byte
Expiration uint64
Rest []rlp.RawValue `rlp:"tail"`
} |
| FINDNODE | 向节点查询某个与目标节点ID距离接近的节点 | type findnode struct {
Target NodeID
Expiration uint64
Rest []rlp.RawValue `rlp:"tail"`
} |
| NEIGHBORS | FIND_NODE命令响应,发送与目标节点ID距离接近的K桶中的节点 | type neighbors struct {
Nodes []rpcNode
Expiration uint64
Rest []rlp.RawValue `rlp:"tail"`
} |
以太坊的底层p2pServer,大约可以分为三层: 1、底层:table对象、node对象,它们分别定义了底层的路由表以及本地节点的数据结构、搜索和验证; 1)datab ...