以太坊源码解读(6)BlockChain 区块插入和校验
以太坊blockchain的管理事务:
- 1、blockchain模块初始化
- 2、blockchain模块插入校验分析
- 3、blockchain模块区块链分叉处理
- 4、blockchian模块规范链更新
上一节分析了blockchain的初始化,这一节来分析blockchain区块的插入和校验分析以及规范链更新。
一、InsertChain函数
主要功能:调用insertChain将一组区块挨个尝试插入数据库和规范链。
- 1、验证每个区块的header;
- 2、验证每个区块的body;
- 3、处理验证header和body所产生的错误;
- 4、如果验证通过,对待插入区块的交易状态进行验证,否则退出;
- 5、如果验证通过,调用WriteBlockWithState将第n个区块插入区块链(写入数据库),然后写入规范链,同时处理分叉问题。
应用场景:
1、导入区块:
admin.importChain
2、ProtocolManager.Downloader主动同步区块:
Downloader.synchronise
—> Downloader.syncWithPeer
—> Downloader.processFullSyncCotent
—> Downloader.importBlockResults
—> BlockChain.InsertChain
3、ProtocolManager.fetcher被动接受其他节点发来的区块:
ProtocolManager.fetcher.insert
—> ProtocolManager.Downloader.BlockChain.InsertChain
InsertChain(chain types.Blocks)源码
func (bc *BlockChain) InsertChain(chain types.Blocks) (int, error) {
n, events, logs, err := bc.insertChain(chain)
bc.PostChainEvents(events, logs)
return n, err
}
InsertChain实际上调用的是insertChain(),然后将导出事件和日志。insertChain()函数代码还是比较多的,它是上述5个功能是实际实现函数,即:
- 1、验证每个区块的header;
- 2、验证每个区块的body;
- 3、处理验证header和body所产生的错误;
- 4、如果验证通过,对待插入区块的交易状态进行验证,否则退出;
- 5、如果验证通过,调用WriteBlockWithState将第n个区块插入区块链(写入数据库),然后写入规范链,同时处理分叉问题。
part 1 Pre-checks,保证待插入的链是有序链接的
func (bc *BlockChain) insertChain(chain types.Blocks) (int, []interface{}, []*types.Log, error) {
// Sanity check that we have something meaningful to import
if len(chain) == 0 {
return 0, nil, nil, nil
}
// 逐个检查区块的区块号是否连续以及hash链是否连续
for i := 1; i < len(chain); i++ {
if chain[i].NumberU64() != chain[i-1].NumberU64()+1 || chain[i].ParentHash() != chain[i-1].Hash() {
// Chain broke ancestry, log a message (programming error) and skip insertion
log.Error("Non contiguous block insert", "number", chain[i].Number(), "hash", chain[i].Hash(),
"parent", chain[i].ParentHash(), "prevnumber", chain[i-1].Number(), "prevhash", chain[i-1].Hash())
return 0, nil, nil, fmt.Errorf("non contiguous insert: item %d is #%d [%x…], item %d is #%d [%x…] (parent [%x…])",
i-1, chain[i-1].NumberU64(),chain[i-1].Hash().Bytes()[:4], i, chain[i].NumberU64(), chain[i].Hash().Bytes()[:4],
chain[i].ParentHash().Bytes()[:4])
}
}
// Pre-checks passed, start the full block imports
bc.wg.Add(1)
defer bc.wg.Done()
bc.chainmu.Lock()
defer bc.chainmu.Unlock()
等所有检验通过以后,使用go语言的waitGroup.Add(1)来增加一个需要等待的goroutine,waitGroup.Done()来减1。在尚未Done()之前,具有waitGroup.wait()的函数就会停止,等待某处的waitGroup.Done()执行完才能执行。这里waitGroup.wait()是在blockchain.Stop()函数里,意味着如果在插入区块的时候,突然有人执行Stop()函数,那么必须要等insertChain()执行完。
part 2 验证第n个区块的header和body
1、准备数据:
- a. headers切片
- b. seals切片(检查headers切片里的每个索引的header是否需要检查)
- c. abort通道和results通道(前者用来传递退出命令,后者用来传递检查结果)
headers := make([]*types.Header, len(chain))
seals := make([]bool, len(chain))
for i, block := range chain {
headers[i] = block.Header()
seals[i] = true
}
abort, results := bc.engine.VerifyHeaders(bc, headers, seals)
defer close(abort)
这里的bc.engine.VerifyHeaders()是一个异步操作,所以结果返回到results通道里,这是go语言实现异步的一种方式。
2、检查区块的正确性
// Iterate over the blocks and insert when the verifier permits
for i, block := range chain {
// 如果inset被取消,则退出进程
if atomic.LoadInt32(&bc.procInterrupt) == 1 {
log.Debug("Premature abort during blocks processing")
break
}
// 如果区块是bad block,直接return
if BadHashes[block.Hash()] {
bc.reportBlock(block, nil, ErrBlacklistedHash)
return i, events, coalescedLogs, ErrBlacklistedHash
}
// Wait for the block's verification to complete
bstart := time.Now()
err := <-results
// 如果results表明验证通过,则进行第二步,验证区块
if err == nil {
err = bc.Validator().ValidateBody(block)
}
atomic.LoadInt32(&bc.procInterrupt)是一个原子变量,在Stop()函数中会被设置成1。也就是说,如果有人调用Stop()函数,该值会被设置成1,然后这里就会 break。
如果验证失败,要怎么处理这些错误?
3. 处理验证header和body所产生的错误
- a. 待插入的区块已经是数据库中存在的
- b. 待插入的是未来区块
- c. 在数据库中找不到待插入区块的父区块但未来区块列表中能找到它的父区块
- d. 待插入区块是数据库中的一个精简分支
switch {
case err == ErrKnownBlock:
// 待插入的区块已经存在于数据库,并且规范链头区块区块号大于该区块的区块号,直接忽略
if bc.CurrentBlock().NumberU64() >= block.NumberU64() {
stats.ignored++
continue
}
case err == consensus.ErrFutureBlock:
// 待插入区块的时间戳大于当前时间15秒,则认为是未来区块
// 待插入区块的时间戳大于当前时间30秒,则直接丢弃这个区块
max := big.NewInt(time.Now().Unix() + maxTimeFutureBlocks)
if block.Time().Cmp(max) > 0 {
return i, events, coalescedLogs, fmt.Errorf("future block: %v > %v", block.Time(), max)
}
bc.futureBlocks.Add(block.Hash(), block)
stats.queued++
continue
case err == consensus.ErrUnknownAncestor && bc.futureBlocks.Contains(block.ParentHash()):
// 数据库里找不到这个区块的父区块,但未来待处理缓冲里有父区块,就将它放入未来待处理缓冲里
bc.futureBlocks.Add(block.Hash(), block)
stats.queued++
continue
case err == consensus.ErrPrunedAncestor:
// 父区块是数据库中的一条精简分支区块(精简分支区块就是一些没有state root的区块)
// 如果这个区块的总难度小于等于规范链的总难度值,只将它写入数据库,不上规范链
currentBlock := bc.CurrentBlock()
localTd := bc.GetTd(currentBlock.Hash(), currentBlock.NumberU64())
externTd := new(big.Int).Add(bc.GetTd(block.ParentHash(), block.NumberU64()-1), block.Difficulty())
if localTd.Cmp(externTd) > 0 {
if err = bc.WriteBlockWithoutState(block, externTd); err != nil {
return i, events, coalescedLogs, err
}
continue
}
// 如果这个区块总难度值大于或等于规范链总难度值,将这个精简链插入规范链
var winner []*types.Block
parent := bc.GetBlock(block.ParentHash(), block.NumberU64()-1)
for !bc.HasState(parent.Root()) {
winner = append(winner, parent)
parent = bc.GetBlock(parent.ParentHash(), parent.NumberU64()-1)
}
for j := 0; j < len(winner)/2; j++ {
winner[j], winner[len(winner)-1-j] = winner[len(winner)-1-j], winner[j]
}
// 递归调用insertChain(),不再需要错误处理,而是按顺序执行交易完善精简区块的state
bc.chainmu.Unlock()
_, evs, logs, err := bc.insertChain(winner)
bc.chainmu.Lock()
events, coalescedLogs = evs, logs
if err != nil {
return i, events, coalescedLogs, err
}
case err != nil:
// 不属于上面四种错误,无法处理,那就直接return
bc.reportBlock(block, nil, err)
return i, events, coalescedLogs, err
}
4. 如果上面验证均通过,则对待插入区块的交易状态进行验证,否则退出
- a. 从父区块读取状态
- b. 执行交易,更新状态:bc.processor.Process(block, state, bc.vmConfig)
- c. 对状态进行验证,看与header中的数据是否匹配
// Create a new statedb using the parent block and report an
// error if it fails.
var parent *types.Block
if i == 0 {
parent = bc.GetBlock(block.ParentHash(), block.NumberU64()-1)
} else {
parent = chain[i-1]
}
// 将这个block的父亲的状态树从数据库中读取出来,并实例化成StateDB
state, err := state.New(parent.Root(), bc.stateCache)
if err != nil {
return i, events, coalescedLogs, err
}
// Process block using the parent state as reference point.
// 使用当前blcok中的交易执行生成新的状态(new state),获取执行结果(收据列表和日志列表)
// 如果执行成功,state会得到一个新的状态
receipts, logs, usedGas, err := bc.processor.Process(block, state, bc.vmConfig)
if err != nil {
bc.reportBlock(block, receipts, err)
return i, events, coalescedLogs, err
}
// Validate the state using the default validator
// 验证状态:用上面执行交易后得到的全新状态对比block中的状态参数
err = bc.Validator().ValidateState(block, parent, state, receipts, usedGas)
if err != nil {
bc.reportBlock(block, receipts, err)
return i, events, coalescedLogs, err
}
proctime := time.Since(bstart)
5、如果验证成功,调用WriteBlockWithState将这个区块插入数据库,然后写入规范链,同时处理分叉问题
- a. 写入数据库,判断是规范链还是分叉:bc.WriteBlockWithState() —> status
- b. 如果是规范链,输出规范链日志,添加ChainEvent事件
- c. 如果是分叉,则输出分叉日志,添加ChainSideEvent事件
// Write the block to the chain and get the status.
// 将区块写入数据库并获得status
status, err := bc.WriteBlockWithState(block, receipts, state)
if err != nil {
return i, events, coalescedLogs, err
}
switch status {
case CanonStatTy: // 如果插入的是规范链
log.Debug("Inserted new block", "number", block.Number(), "hash", block.Hash(), "uncles", len(block.Uncles()),
"txs", len(block.Transactions()), "gas", block.GasUsed(), "elapsed", common.PrettyDuration(time.Since(bstart)))
coalescedLogs = append(coalescedLogs, logs...)
blockInsertTimer.UpdateSince(bstart)
events = append(events, ChainEvent{block, block.Hash(), logs})
lastCanon = block
// Only count canonical blocks for GC processing time
bc.gcproc += proctime
case SideStatTy: // 如果插入的是分叉
log.Debug("Inserted forked block", "number", block.Number(), "hash", block.Hash(), "diff", block.Difficulty(), "elapsed",
common.PrettyDuration(time.Since(bstart)), "txs", len(block.Transactions()), "gas", block.GasUsed(), "uncles", len(block.Uncles()))
blockInsertTimer.UpdateSince(bstart)
events = append(events, ChainSideEvent{block})
}
stats.processed++
stats.usedGas += usedGas
cache, _ := bc.stateCache.TrieDB().Size()
stats.report(chain, i, cache)
part 3 跳出循环,检验插入的区块是否是头区块,并报告事件
// Append a single chain head event if we've progressed the chain
if lastCanon != nil && bc.CurrentBlock().Hash() == lastCanon.Hash() {
events = append(events, ChainHeadEvent{lastCanon})
}
return 0, events, coalescedLogs, nil
函数最后返回了所有的事件(上链事件、分叉事件、头区块事件)以及所有的日志。
思考一个问题,为什么插入一个区块需要返回这些事件和日志?用于通知给订阅了区块插入事件的对象!
我们在blockchain类中曾经看到过这样的定义:
rmLogsFeed event.Feed chainFeed event.Feed chainSideFeed event.Feed chainHeadFeed event.Feed logsFeed event.Feed scope event.SubscriptionScope
我们通过event.Feed这个模块来监听事件。以插入规范链事件为例,实际上,在我们通过rpc对象调用智能合约的函数的时候,需要发布一个交易,然后客户端处于pending状态等待上链。当包涵这个交易的区块插入规范链的时候,rpc对象绑定的feed模块就会产看这个上链事件的区块中是否包含刚才的交易,如果有则到相应的receipt中拿到调用函数的返回值,再包装成rpc格式的数据返回客户端。(Feed模块我们以后再看)
二、WriteBlockWithState()函数详解
上面第5步的调用,即由BlockChain.insertChain()调用,主要功能:将一个区块写入数据库和规范链
- 1、将区块总难度插入数据库
- 2、将区块header和body写入数据库
- 3、新的状态树写入数据库
- 4、将区块的收据列表写入数据库
- 5、将区块写入规范链(BlockChain.insert),同时处理分叉(BlockChain.reorg)
func (bc *BlockChain) WriteBlockWithState(block *types.Block, receipts []*types.Receipt, state *state.StateDB) (status WriteStatus, err error) {
bc.wg.Add(1)
defer bc.wg.Done()
// 获取父区块总难度
ptd := bc.GetTd(block.ParentHash(), block.NumberU64()-1)
if ptd == nil {
return NonStatTy, consensus.ErrUnknownAncestor
}
// Make sure no inconsistent state is leaked during insertion
bc.mu.Lock()
defer bc.mu.Unlock()
// 获取当前本地规范链头区块的总难度
currentBlock := bc.CurrentBlock()
localTd := bc.GetTd(currentBlock.Hash(), currentBlock.NumberU64())
// 计算待插入区块的总难度
externTd := new(big.Int).Add(block.Difficulty(), ptd)
// step 1 将插入后的总难度写入数据库,'h'+ num + hash + 't'作为key
if err := bc.hc.WriteTd(block.Hash(), block.NumberU64(), externTd); err != nil {
return NonStatTy, err
}
// step 2 使用数据库的Write接口将block(header,body)写入数据库
// header的key为:'h' + num + hash
// body的key为:'b' + num +hahs
rawdb.WriteBlock(bc.db, block)
// step 3 将新的状态树内容写入数据库
root, err := state.Commit(bc.chainConfig.IsEIP158(block.Number()))
if err != nil {
return NonStatTy, err
}
triedb := bc.stateCache.TrieDB()
// If we're running an archive node, always flush
if bc.cacheConfig.Disabled {
if err := triedb.Commit(root, false); err != nil {
return NonStatTy, err
}
} else {
// Full but not archive node, do proper garbage collection
triedb.Reference(root, common.Hash{}) // metadata reference to keep trie alive
bc.triegc.Push(root, -float32(block.NumberU64()))
if current := block.NumberU64(); current > triesInMemory {
// If we exceeded our memory allowance, flush matured singleton nodes to disk
var (
nodes, imgs = triedb.Size()
limit = common.StorageSize(bc.cacheConfig.TrieNodeLimit) * 1024 * 1024
)
if nodes > limit || imgs > 4*1024*1024 {
triedb.Cap(limit - ethdb.IdealBatchSize)
}
// Find the next state trie we need to commit
header := bc.GetHeaderByNumber(current - triesInMemory)
chosen := header.Number.Uint64()
// If we exceeded out time allowance, flush an entire trie to disk
if bc.gcproc > bc.cacheConfig.TrieTimeLimit {
// If we're exceeding limits but haven't reached a large enough memory gap,
// warn the user that the system is becoming unstable.
if chosen < lastWrite+triesInMemory && bc.gcproc >= 2*bc.cacheConfig.TrieTimeLimit {
log.Info("State in memory for too long, committing", "time", bc.gcproc, "allowance", bc.cacheConfig.TrieTimeLimit, "optimum", float64(chosen-lastWrite)/triesInMemory)
}
// Flush an entire trie and restart the counters
triedb.Commit(header.Root, true)
lastWrite = chosen
bc.gcproc = 0
}
// Garbage collect anything below our required write retention
for !bc.triegc.Empty() {
root, number := bc.triegc.Pop()
if uint64(-number) > chosen {
bc.triegc.Push(root, number)
break
}
triedb.Dereference(root.(common.Hash))
}
}
}
// step 4 将收据内容写入数据库
// 使用'r' + num + hash作为key,receipt列表的RLP编码值作为value
batch := bc.db.NewBatch()
rawdb.WriteReceipts(batch, block.Hash(), block.NumberU64(), receipts)
// 将待插入的区块写入规范链
// 如果待插入区块的总难度等于本地规范链的总难度,但是区块号小于或等于当前规范链的头区块号,均认为待插入的区块所在分叉更有效,需要处理分叉并更新规范链
reorg := externTd.Cmp(localTd) > 0
currentBlock = bc.CurrentBlock()
if !reorg && externTd.Cmp(localTd) == 0 {
// Split same-difficulty blocks by number, then at random
reorg = block.NumberU64() < currentBlock.NumberU64() || (block.NumberU64() == currentBlock.NumberU64() && mrand.Float64() < 0.5)
}
// 如果待插入区块的总难度大于本地规范链的总难度,那Block必定要插入规范链
// 如果待插入区块的总难度小雨本地规范链的总难度,待插入区块在另一个分叉上,不用插入规范链
if reorg {
// Reorganise the chain if the parent is not the head block
if block.ParentHash() != currentBlock.Hash() {
if err := bc.reorg(currentBlock, block); err != nil {
return NonStatTy, err
}
}
// 写入交易查询入口信息
rawdb.WriteTxLookupEntries(batch, block)
rawdb.WritePreimages(batch, block.NumberU64(), state.Preimages())
status = CanonStatTy
} else {
status = SideStatTy
}
// 将batch数据缓冲写入数据库,调用batch的Write()方法
if err := batch.Write(); err != nil {
return NonStatTy, err
}
// Set new head.
if status == CanonStatTy {
// 如果这个区块可以插入本地规范链,就将它插入
// step 1 更新规范链上区块号对应的hash值
// step 2 更新数据库中的“LastBlock”的值
// step 3 更新BlockChain的CurrentBlock
// step 4 纠正HeaderChain的错误延伸
bc.insert(block)
}
// 从futureBlock中删除刚才插入的区块
bc.futureBlocks.Remove(block.Hash())
return status, nil
}
这里还有一个是需要注意的,就是如果我们的这个待插入区块总难度大于规范链的总难度的,最理想的情况就是该区块的父区块就是规范链的最前一个区块,这样就直接将balock上链就可以了。但是有一种情况是,待插入的区块的父区块不是currentBlock,有可能它的父区块是currentBlock之前的一个区块,而总难度更大的原因是因为td(thisBlock) > td(currentBlock)。这就意味着,这个待添加到区块是在另一个分叉上,而我们现在需要将该分叉视作新的规范链。这时候需要调用BlockChain.reorg()方法。
三、reorg()函数
reorg()函数的主要功能就是处理分叉:将原来的分叉链设置成规范链,将旧规范链上存在但新规范链上不存在的交易信息找出来,删除他们在数据库中的查询入口信息。
原理:
- 1、找出新链和老链的共同祖先;
- 2、将新链插入到规范链中,同时收集插入到规范链中的所有交易;
- 3、找出待删除列表中的那些不在待添加的交易列表的交易,并从数据库中删除它们的交易查询入口
- 4、向外发送区块被重新组织的事件,以及日志删除的事件
执行这个方法的前提是:newBlock的总难度大于oldBlock,且newBlock的父区块不是oldBlock。
func (bc *BlockChain) reorg(oldBlock, newBlock *types.Block) error {
var (
newChain types.Blocks
oldChain types.Blocks
commonBlock *types.Block
deletedTxs types.Transactions
deletedLogs []*types.Log
// collectLogs collects the logs that were generated during the
// processing of the block that corresponds with the given hash.
// These logs are later announced as deleted.
collectLogs = func(hash common.Hash) {
// Coalesce logs and set 'Removed'.
number := bc.hc.GetBlockNumber(hash)
if number == nil {
return
}
receipts := rawdb.ReadReceipts(bc.db, hash, *number)
for _, receipt := range receipts {
for _, log := range receipt.Logs {
del := *log
del.Removed = true
deletedLogs = append(deletedLogs, &del)
}
}
}
)
// 第一步:找到新链和老链的共同祖先
if oldBlock.NumberU64() > newBlock.NumberU64() {
// 如果老分支比心分支区块高度高,则减少老分支直到与新分支高度相同
// 并收集老分支上的交易和日志
for ; oldBlock != nil && oldBlock.NumberU64() != newBlock.NumberU64(); oldBlock = bc.GetBlock(oldBlock.ParentHash(), oldBlock.NumberU64()-1) {
oldChain = append(oldChain, oldBlock)
deletedTxs = append(deletedTxs, oldBlock.Transactions()...)
collectLogs(oldBlock.Hash())
}
} else {
// 如果新分支高于老分支,则减少新分支
for ; newBlock != nil && newBlock.NumberU64() != oldBlock.NumberU64(); newBlock = bc.GetBlock(newBlock.ParentHash(), newBlock.NumberU64()-1) {
newChain = append(newChain, newBlock)
}
}
if oldBlock == nil {
return fmt.Errorf("Invalid old chain")
}
if newBlock == nil {
return fmt.Errorf("Invalid new chain")
}
// 等到共同高度后,去找到共同祖先(共同回退),继续收集日志和事件
for {
if oldBlock.Hash() == newBlock.Hash() {
commonBlock = oldBlock
break
}
oldChain = append(oldChain, oldBlock)
newChain = append(newChain, newBlock)
deletedTxs = append(deletedTxs, oldBlock.Transactions()...)
collectLogs(oldBlock.Hash())
oldBlock, newBlock = bc.GetBlock(oldBlock.ParentHash(), oldBlock.NumberU64()-1), bc.GetBlock(newBlock.ParentHash(), newBlock.NumberU64()-1)
if oldBlock == nil {
return fmt.Errorf("Invalid old chain")
}
if newBlock == nil {
return fmt.Errorf("Invalid new chain")
}
}
// Ensure the user sees large reorgs
// 打印规则(不影响核心功能)
if len(oldChain) > 0 && len(newChain) > 0 {
logFn := log.Debug
if len(oldChain) > 63 {
logFn = log.Warn
}
logFn("Chain split detected", "number", commonBlock.Number(), "hash", commonBlock.Hash(),
"drop", len(oldChain), "dropfrom", oldChain[0].Hash(), "add", len(newChain), "addfrom", newChain[0].Hash())
} else {
log.Error("Impossible reorg, please file an issue", "oldnum", oldBlock.Number(), "oldhash", oldBlock.Hash(), "newnum", newBlock.Number(), "newhash", newBlock.Hash())
}
// 第二步:将新链插入到规范链中,同时收集插入到规范链中的所有交易
for i := len(newChain) - 1; i >= 0; i-- {
// insert the block in the canonical way, re-writing history
bc.insert(newChain[i])
// 把所有新分支的区块交易查询入口插入数据库
rawdb.WriteTxLookupEntries(bc.db, newChain[i])
addedTxs = append(addedTxs, newChain[i].Transactions()...)
}
// 第三步:找出待删除列表和待添加列表中的差异,删除那些不在新链上的交易在数据库中的查询入口
diff := types.TxDifference(deletedTxs, addedTxs)
// When transactions get deleted from the database that means the
// receipts that were created in the fork must also be deleted
batch := bc.db.NewBatch()
for _, tx := range diff {
rawdb.DeleteTxLookupEntry(batch, tx.Hash())
}
batch.Write()
// 第四步:向外发送区块被重新组织的事件,以及日志删除事件
if len(deletedLogs) > 0 {
go bc.rmLogsFeed.Send(RemovedLogsEvent{deletedLogs})
}
if len(oldChain) > 0 {
go func() {
for _, block := range oldChain {
bc.chainSideFeed.Send(ChainSideEvent{Block: block})
}
}()
}
return nil
}
四、insert()函数
func (bc *BlockChain) insert(block *types.Block) {
// 读出待插入blcok的区块号对应在规范链上的区块hash值,与block的hash值对比看是否相等,即判断HeaderChain延伸是否正确,如果不正确,后面矫正
updateHeads := rawdb.ReadCanonicalHash(bc.db, block.NumberU64()) != block.Hash()
// 更新规范链上block.number的hash值为block.hash
rawdb.WriteCanonicalHash(bc.db, block.Hash(), block.NumberU64())
// 正式写入规范链,更新数据库中的LastBlock
rawdb.WriteHeadBlockHash(bc.db, block.Hash())
// 将BlockChain中的currentBlock替换成blcok
bc.currentBlock.Store(block)
// If the block is better than our head or is on a different chain, force update heads
if updateHeads {
// 将headerChain的头设置成待插入规范链的区块头,BlockChain和HeaderChain在此齐头并进
bc.hc.SetCurrentHeader(block.Header())
rawdb.WriteHeadFastBlockHash(bc.db, block.Hash())
bc.currentFastBlock.Store(block)
}
}
五、总结:
区块链的插入新区块的流程: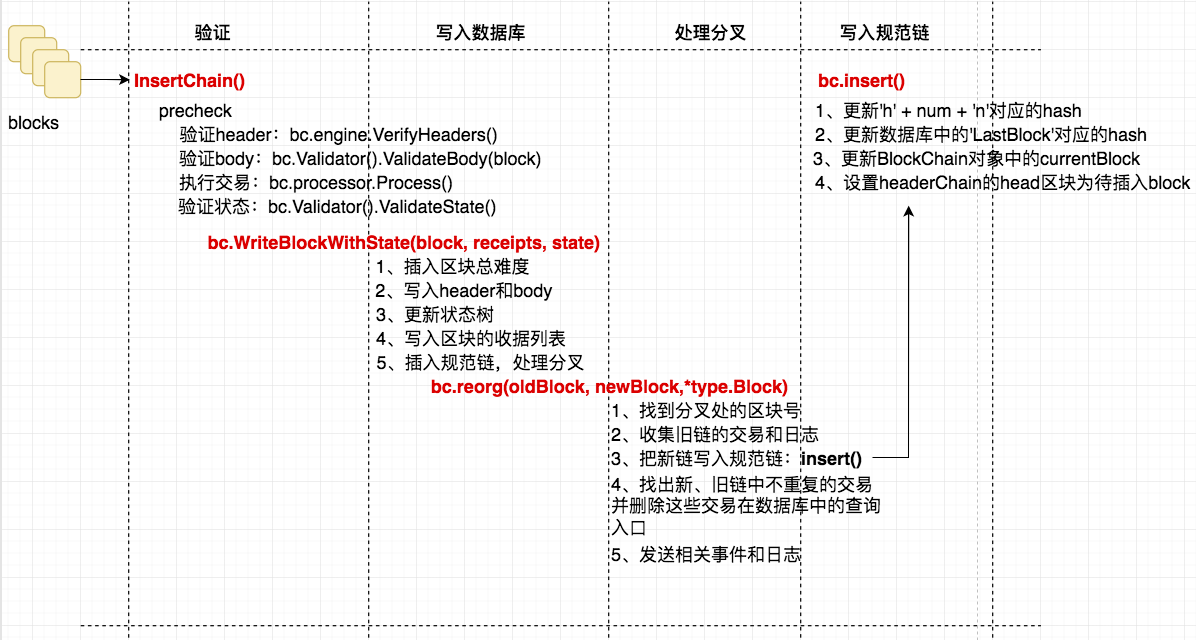
一、分布式网络的来历 基于P2P技术的应用有很多,包括文件分享,即时通信,协同处理,流媒体通信等等。其中文件分享和下载是p2p技术最集中体现。其中,DHT技术是目前很多分布式系统所普遍采用的方案,也包 ...